

1.创新工场董事长兼零一万物CEO李开复预测,2025年将迎来大模型应用爆发元年。
2.AI模型进化加速,从OpenAI的o1到o3仅用3个月,DeepSeek的R1也快速迭代。
3.由于DeepSeek的开源,成功唤醒中国市场需求,成为推动国内To B/To C应用全面启动的关键力量。
4.然而,大模型应用仍面临实际问题,如本地简单部署、数据安全、联网搜索等。
5.为此,零一万物正在推动小语种模型,并希望与“一带一路”沿线国家合作,帮助他们建设自主可控的本地化模型。
以上内容由腾讯混元大模型生成,仅供参考
李开复:全球视角下的生成式AI展望|未来人工智能先锋论坛
腾讯科技特约作者 燕妮
编辑 郑可君
3月29日,2025中关村论坛在北京召开,创新工场董事长兼零一万物CEO李开复发表主题为《全球视角下的生成式AI展望》的演讲,李开复认为:
1、2025年将成为大模型应用爆发元年。推理成本持续下降、模型性能提升显著,加上“文理兼修”的训练策略,使得大模型实用性大增。
2、“AI教AI”正在加速模型进化。从OpenAI o1到o3仅用3个月,DeepSeek r1也快速迭代,得益于AI具备“慢思考”“反思”和“自我进步”能力。
3、DeepSeek 开源引爆中国“ChatGPT Moment”。DeepSeek不仅以极快速度实现高推理能力,还选择了开源,成功唤醒中国市场需求,成为推动国内To B/To C应用全面启动的关键力量。
以下为李开复在中关村论坛的主题演讲,经腾讯科技编辑整理:
我们都知道,大模型带来了巨大的生产力革命。过去两年多,自从ChatGPT推出以来,大模型的智能水平持续提升,完全没有停下脚步,推理成本每年降低10倍。两年前那些“不够好”的模型,现在已经足够用了;两年前价格昂贵的模型,如今也变得“白菜价”。
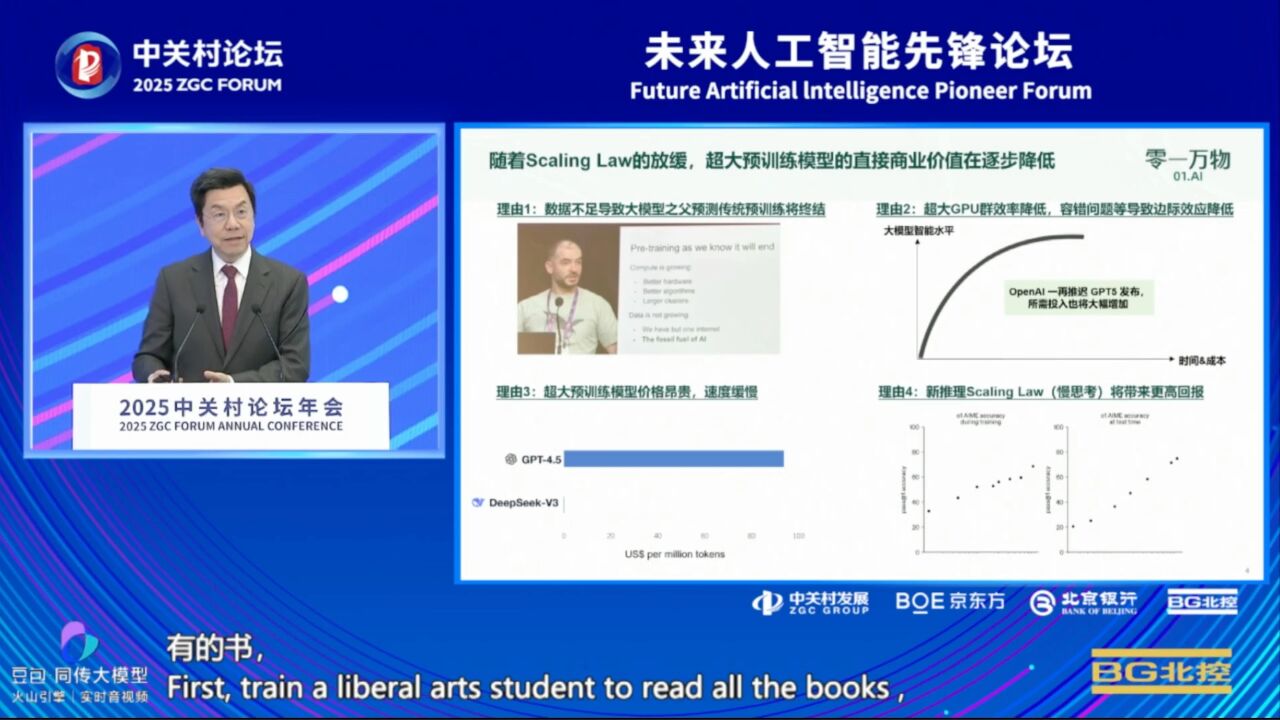
随着各种技术的不断进步,我认为2025年必将成为应用爆发、落地的井喷之年。当然,我们也知道几个月前Ilya提到,Scaling Law在预训练方面似乎已趋于放缓,原因包括数据量不足、GPU扩增带来的收益递减。例如,GPU数量增加10倍,性能提升却仅有2倍。即使训练出了超大模型,比如GPT-4.5确实表现不俗,但成本却是DeepSeek的500倍,因此,这类超大模型在实际应用中并不实用。
不过,值得庆幸的是,我们看到了新的曙光,Scaling Law的重点,正在从“预训练”转向“推理中的慢思考模式”。这意味着,原来通过“更多GPU + 更多数据”使模型变聪明的方式已经放缓,而“慢思考”则代表模型在思考时间更长的情况下可以产出更优结果。也就是说,大模型的成长仍然很快,而且这才刚刚开始。
在这些新技术的结合下,如今的大模型训练方式也发生了重要变化——先训练一个“文科生”,让它读所有的书,再训练一个“理科生”,让它会解数学题、写代码。这样打造出来的“文武双全”模型能力非常强大,这是我们过去几个月看到的一项重大进展。
虽然今天我们或许已经普遍了解这一点,但如果往前推六个月,当时很少有人意识到训练流程会采用“先文后理”的方式。这种模式的出现,本身就非常值得关注。
另一个值得注意的现象是,AI的进步周期正在加速,而不是放缓。我们可能还记得,从GPT-2到GPT-3,再到GPT-4.5,每次迭代大约都花了两年时间。为什么这么慢?因为本质上还是“人”在主导训练——人类需要设计新算法、新模型架构,调配GPU资源,收集数据,才能推动模型进步。
但今天,我们进入了一个全新的时代——AI开始训练AI。从OpenAI的o1到o3只用了三个月,DeepSeek的R1在o1之后两个月发布,R2很快也会到来。这种“三个月一个周期”的现象,为何出现?因为如今的学习过程,已经不再依赖人类继续发明新算法或架构,而是AI具备了“慢思考”“反思”和“自我进步”的能力。
AI可以教AI。通过“慢思考”,AI能变得更聪明;而通过“更聪明的AI”去训练“较弱的AI”,也就是用超大模型做“老师”,训练小模型作为“学生”,再配合蒸馏、数据标注与合成技术,模型的进步速度将大大加快。这意味着,训练的瓶颈不再是人类,AI可以自我进化。
最近,大家都在讨论DeepSeek,我也分享一下自己对DeepSeek的四点观察:
1、推理能力强且原生构建
DeepSeek非常快地达到了严谨推理能力,并非通过蒸馏获得,而是从底层原生实现。此外,它还公开了“思维链”,这一点令人震撼。因为OpenAI将其思维链视为机密,从不公开,担心被模仿。而DeepSeek却从第一性原理出发,从零构建并开放,这是极为罕见的成就。
2、工程效率极高
关于其推理速度,不同渠道有不同说法。但公平比较来看,我认为它的速度比美国同类模型快了5~10倍,成本也大幅下降,这是极具突破性的工程进步。
3、验证了开源的力量
DeepSeek证明了闭源是一条死路,开源才是未来发展的关键。如果DeepSeek没有选择开源,我认为它绝不可能获得今天的影响力。我们也看到,美国的开源社区和社交媒体对DeepSeek热情拥抱,这是前所未有的。从来没有一个中国软件在海外获得如此高度的欢迎,这种对比也突显了OpenAI的闭塞与DeepSeek的开放之间的差异。
4、中国迎来“DeepSeek Moment”
大约9个月前,我曾表示很沮丧:中国没有自己的“ChatGPT Moment”。虽然已有一些不错的大模型,但并未出现一个“出类拔萃”的产品引发全民应用热潮,也没有促使每位CEO都去问IT部门“什么时候部署大模型”,但现在,这一切改变了。DeepSeek的成功唤醒了中国市场,而教育市场原本是产品落地最大的瓶颈。如果新创企业还需要去“教育市场”,几乎没有成功的可能,因为周期太长、不确定性太高。
如今,DeepSeek已经为中国的To B、To C应用完成了市场教育。因此,我相信大模型应用时代已经具备了更多“必然来临”的理由。当然,DeepSeek模型本身很强,但若要真正落地到企业,还需要考虑几个实际问题:
1、企业老板普遍希望模型可以本地简单部署、数据安全、无需API连接;
2、应用层面,企业往往还需要联网搜索、深度调研(Deep Research)能力;
3、企业还希望模型能与内部系统对接,如ERP、CRM,甚至能在此基础上开发软件或智能体,实现快速构建企业内部应用;
4、此外,微调甚至进一步预训练仍是部分企业的需求。
基于这些考量,零一万物在过去几个月也进行了战略调整,我们将大部分力量投向以DeepSeek为核心的企业级解决方案。刚才提到的那些技术,包括安全部署、应用实践、行业定制,我们都已实现。值得注意的是,这些能力只有具备大模型研发经验的公司才能完成,普通软件公司或系统集成商并不具备这方面的认知与能力。
最后,我想提一个很少被讨论的问题:如今,全球都在拥抱大模型,但非主流语言的表现仍然很差。比如,我们用俄语作为例子:LLaMA仅用0.13%的训练数据处理俄语,所以效果非常差。如果再看东南亚、中东、中亚、非洲等地区,情况更糟,几乎难以使用。
我有一位朋友是斯坦福的语言学教授,他指出,大模型基本忽视了全球约7000种小语种。这可能会带来严重后果:这些语言由于无法被大模型支持,反而会加速“灭绝”。
康奈尔大学的研究也指出,大模型在训练中倾向采用欧美的价值观。在他们绘制的图中可以看到,西欧和美国国家的价值观集中在一个椭圆区域内,大模型也几乎都处于该区域。相对而言,亚洲、非洲、中东的价值观则存在明显偏差。因此,每个国家都应有机会训练拥有自己语言和价值观的大模型。
中国在这方面相对幸运,有很多公司在做这件事。但其他小语种国家则面临更大困难。因此,零一万物正在推动小语种模型,并希望与“一带一路”沿线国家合作,帮助他们建设自主可控的本地化模型。
综上所述,我认为:今年开源是大事;DeepSeek是大事;AI 应用爆发即将到来;各家模型公司必须回归商业本质,思考如何真正创造客户价值。
我们的年度口号就是:Make AI Work。
谢谢大家。