

1.DeepSeek V3-0324版本发布,百科知识、数学和代码任务表现均有提升,全面超越Claude-3.7-Sonnet。
2.该模型在推理类任务上表现出色,与Grok-3持平,并列传统对话类模型榜首。
3.与此同时,DeepSeek-V3-0324的输入价格仅为Claude-3.7-Sonnet的1/11,GPT-4.5的1/277,具有较高性价比。
4.除此之外,新版V3在诸多日常场景如前端开发能力、中文搜索能力和中文写作能力等方面也有提升。
5.最后,DeepSeek-V3-0324采用MIT许可证,可免费用于商业用途,2025年将开启真正的DeepSeek时代。
以上内容由腾讯混元大模型生成,仅供参考
昨天,DeepSeek 在毫无预告的情况下,悄悄上线了 DeepSeek-V3-0324——看似“小版本更新”的模型,经过一天的发酵,已经引发了一波地震。
但我没想到的是,就在刚刚,发生了一波真的地震——
好家伙,坐标北京海淀的我,都快写稿子写睡着了,结果突然感觉到有人在晃我的床。
翻了翻朋友圈才知道,这 DeepSeek-V3 的震感这次是真的从精神层面传导到我的肉体层面了...
当然,以上纯瞎扯,物理地震与 DeepSeek 新模型发布无任何关联。但愿震中地区的家人们无人受伤...
下面进入正题。
先贴官方给出的评测结果——
新版 DeepSeek-V3-0324 模型的百科知识(MMLU-Pro, GPQA)、数学(MATH-500, AIME 2024)和代码任务(LiveCodeBench)表现均有提升。
划重点——
全面超越 Claude-3.7-Sonnet 在数学、代码类相关评测集上超过 GPT-4.5
作为一个没有思维链的非推理模型,DeepSeek-V3-0324 模型在推理类任务上的表现可圈可点。
根据第三方评测,新版的 DeepSeek-V3 模型与 Grok-3 打平,并列传统对话类模型榜首。
在真实世界编程基准 Arena 榜单上,有热心网友整理了最新排名——
DeepSeek-V3-0324 模型在该测试基准上,表现仅次于 Claude-3.7-Sonnet-Thinking 和 Claude-3.5-Sonnet。领先 OpenAI o1、Gemini-2.0-Pro、Grok-3-Reasoning 等一众海外知名的推理类&传统对话类模型,当然,也包括 DeepSeek-R1。
如果你觉得 DeepSeek-V3-0324 模型在推理类任务上比肩 Claude-3.7-Sonnet,GPT-4.5 等海外模型还不够刺激,那么算一笔账就明白为什么这个模型会引发地震了。
好家伙,效果差不多的模型,DeepSeek-V3-0324 的输入价格是 Claude-3.7-Sonnet 的 1/11,GPT-4.5 的 1/277。
这直接把 OpenAI 公司和 Anthropic 公司的价格体系给卷崩了啊。
不止是传统对话类模型,即便是 o3-mini 这种推理类模型,有网友评测,发现其也被 DeepSeek-V3-0324 在多种编程语言的测试基准 Aider Polyglot 上彻底击碎了性价比...
要知道,o3-mini 是 OpenAI 放出来卷价格战的,定价上依然要比 DeepSeek-V3 模型贵 4-8 倍。而且,用 o3-mini 的话,你还要为一大串不可见的思维链内容付费,在 DeepSeek-V3-0324 面前,再去用 o3-mini 简直就成了冤大头。
此外,不止是推理类的榜单测评,根据官方的介绍,DeepSeek-V3-0324 模型在诸多日常场景都有了不错的提升。
前端开发能力增强(官方 showcase)
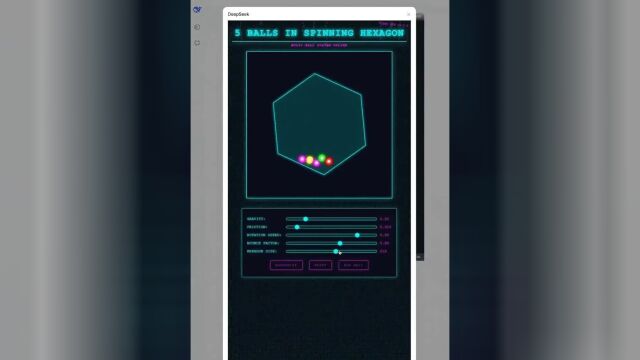
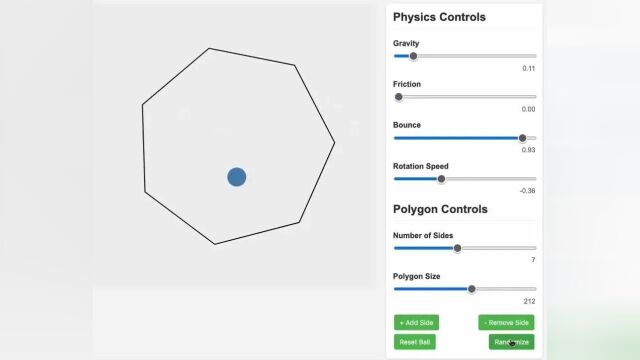
有 X 网友用「难度升级版」的小球碰撞测试来验证 V3 的编程技能,包括重力、摩擦力、弹性、旋转速度控制,还有多边形的边数、尺寸调节。
此外,中文搜索能力优化和中文写作能力也做了升级。
根据官方介绍,新版 V3 在联网搜索场景下,对于报告生成类指令输出内容更为详实准确,且排版更加清晰美观。
技术升级
根据官方的介绍,DeepSeek-V3-0324 模型参数量约 660B,不是网上谣传的 680B。且仅改进了后训练方法,便获得了巨大的效果提升。
值得一提的是,官方在发布该模型时,是先将模型开源,上传 HuggingFace,然后才发的公告。可以看出 DeepSeek 势必是要将开源贯彻到底的决心了。
此外,这次开源同样是 MIT 许可证——可以免费用于商业用途。
而且,根据网友的测试,该模型在价值 10,000 美元的 Mac Studio M3 Ultra 上就能跑起来,吞吐率大概能达到每秒 20 个 Tokens,考虑到不需要等待思维链内容,日常是足够用了。
2025 开始,是真正的 DeepSeek 时代。

