
本文通过分析一段使用 ConcurrentHashMap 的代码发现,该段代码在 JDK 24 中比 JDK 23 快了 20% 以上,这一性能提升源于 JVM 对标量替换优化的改进。文章详细介绍了逃逸分析和标量替换的工作原理,以及它们如何影响对象的内存分配。此外,文章还讨论了 Java 内存管理的复杂性及其对 JVM 实现的影响,强调了 GC 在现代 Java 应用中的重要性。首先来看一段 Java 代码:
int sumMapElements(ConcurrentHashMap<Integer, Integer> map) { int sum = 0; Enumeration<Integer> it = map.elements(); while (it.hasMoreElements()) { sum += (int) it.nextElement(); } return sum;}
函数 sumMapElements 使用迭代器遍历了 ConcurrentHashMap 参数的所有元素,并求了它们的总和,将结果作为返回值返回。
整个代码在实现上相当直观,也没什么弯弯绕绕。我敢说,如果让你来实现一个类似的操作,你十有八九也会写出差不多的代码——或者从不知道哪搜出来的二手 C**N 文章里偷一段。
作为一个非常基础的容器,ConcurrentHashMap 在并发场景里有着广泛的应用。成千上万个日日夜夜里,这段代码的灵魂——也就是里面的那个迭代器,伴随着网卡缓冲区里的车水马龙,流淌在无数台跑着 Java 应用的服务器中。
然而,当你用 OpenJDK 23 和 24,用默认的 G1 GC,分别运行同样的代码(需要 JMH),你会发现一个令人震撼的事实:
23 居然比 24 慢了 20% 还多!
准确地说:类似的代码,在最新的 JDK 下,在不同环境、不同架构中,相比之前均会有不同程度的性能提升。少则 10%,多则超过 30%!
尽管 23 到 24 之间新增了相当多的优化,但我还是确信:你的哈希表变快了,只是因为 JVM 中的一个逻辑漏洞被修好了。
为什么呢?因为这个优化,正是我给 OpenJDK 提交的。战绩可查:JDK-8333334 PRhttps://github.com/openjdk/jdk/pull/19496
而这个优化背后的故事,又和上次的 Shenandoah GC bug 一样,扑朔迷离,荡气回肠。详见文章《JVM/编译器/CPU,究竟谁是卧底?一个曾经困扰我一个月的 bug》。
事实上,这个问题本来永远都不会被发现的。直到某天,我在跑类似代码的时候,给 JVM 添加了一个 -XX:+PrintEliminateAllocations 参数,然后看到了这样的结果:NotScalar (Field load) 124 CheckCastPP === 121 119 [[ 1820 1790 ... ]] ... !jvms: ConcurrentHashMap::elements @ bci:16 (line 2164) HashMap::sumMapElements @ bci:3 (line 38) HashMap::hashMapSum @ bci:5 (line 33) >>>> 964 LoadN === _ 2074 223 [[ 965 2176 ]] ... !jvms: ConcurrentHashMap$BaseIterator::hasMoreElements @ bci:1 (line 3444) HashMap::sumMapElements @ bci:8 (line 39) HashMap::hashMapSum @ bci:5 (line 33)NotScalar (Field load) 124 CheckCastPP === 121 119 [[ 1820 1790 ... ]] ... !jvms: ConcurrentHashMap::elements @ bci:16 (line 2164) HashMap::sumMapElements @ bci:3 (line 38) HashMap::hashMapSum @ bci:5 (line 33) >>>> 2195 LoadI === _ 1971 211 [[ 3042 2937 ]] ... !jvms: ... ConcurrentHashMap$ValueIterator::nextElement @ bci:1 (line 3492) HashMap::sumMapElements @ bci:18 (line 40) HashMap::hashMapSum @ bci:5 (line 33)
注:如需复现,你可能需要自己从源码编译一个 fastdebug 版的 JDK 23,因为 release 版不支持 PrintEliminateAllocations。
这是什么意思?一句话解释:这代表逃逸分析及其之后的 PhaseMacroExpand 试图对 sumMapElements 中的哈希表迭代器进行优化,但失败了,最终导致迭代器分配到了堆上。但从逻辑上讲,这个方法里的迭代器只在方法内被使用过,完全没被传给其他的方法,因此是一个彻彻底底的局部变量——所以它本不应该被放在堆上。作为一个合格的、嗅觉敏锐的 HotSpot JVM 维护者,你应该很快意识到,JVM 在这块肯定有哪里没写对。当然,我并不是个合格的嗅觉敏锐的维护者,这个问题是我主管发现的,我还是太菜了😢而作为一个普通的 Java 程序员,相信你看了这个结果之后……什么?你说你看不懂?没关系,我会用尽可能通俗的语言讲给你听。
如果要问 Java 相比 C++ 最大的优势是什么?相信很多人都会说:Java 不需要手动管理内存。C++ 程序员是这样的,我们 Java 程序员只需要无脑 new 一把梭就可以,可是 C++ 要考虑的事情就很多了:什么 unique_ptr、弱引用、placement new……稍有不慎就会内存泄漏。然而软工祖师爷 Fred Brooks 曾经说过:没有银弹。Java 的内存管理既要接口简单,又要高性能,无疑会导致支撑着一切的 JVM 的实现变得无比复杂。Java 程序员写得爽,那都是背后的 JVM 工程师在负重前行。最直观的体现就是,在 Java 中,有各种复杂的垃圾收集(Garbage Collection,GC)机制:分代、并发、低时延、高吞吐……说 GC 是人类工程智慧的结晶都不为过。这种复杂性还波及了 Java 程序员自己:GC 调参一度成了他们的必备技能,甚至逐渐失控,发展成了玄学。当然,现代 Java 中,在更先进 GC 的加持下(如 ZGC,以及我们团队的 Jade),程序员基本不需要再操心 GC 参数的事了。另一方面,复杂的 GC 会带来更复杂的 bug:比如之前我介绍过的 RISC-V Shenandoah GC 问题,只因原子内存操作的一个 bug,整个 JVM 进程顷刻灰飞烟灭。详见文章《JVM/编译器/CPU,究竟谁是卧底?一个曾经困扰我一个月的 bug》。除此之外,GC 在 JVM 中的影响几乎无处不在。或者说,为了适配 GC 的存在,JVM(HotSpot)不得不把 GC 的逻辑耦合到各种本来和 GC 无关的地方去。
图片来源于网络
一个最典型的例子是 GC barrier。简而言之:GC 需要定期根据对象之间的引用关系,删除那些已经不会被程序用到的对象。而为了更好的维护对象的引用关系,GC 会在一些情况下,向 JVM 生成的代码中插入 barrier,从而避免一些诸如并发的问题。以文章开头提到的 G1 GC 为例。在你对某个对象的字段进行赋值操作时,例如 obj.field = new_value,G1 会要求 JVM 的 JIT 编译器生成两类 barrier:- 一类是 pre-write barrier,出现在赋值之前,用来维护 Snapshot-At-The-Beginning(SATB);
- 另一类是 post-write barrier,用来更新 Remembered Sets(RSets)。
对于具体的术语,篇幅所限,此处无法展开。读者如有兴趣,可参考这篇文章:
https://www.oracle.com/technical-resources/articles/java/g1gc.html所以,虽然你没在代码里写任何和内存管理相关的内容,但为了保证 GC 的正常运转,JVM 不得不偷偷往你的代码里塞一些“私货”。下图就是你写的 Java 代码在 JIT 编译器眼中的样子,其中赫然出现的 write_ref_field_post_entry 调用就是 post-write barrier。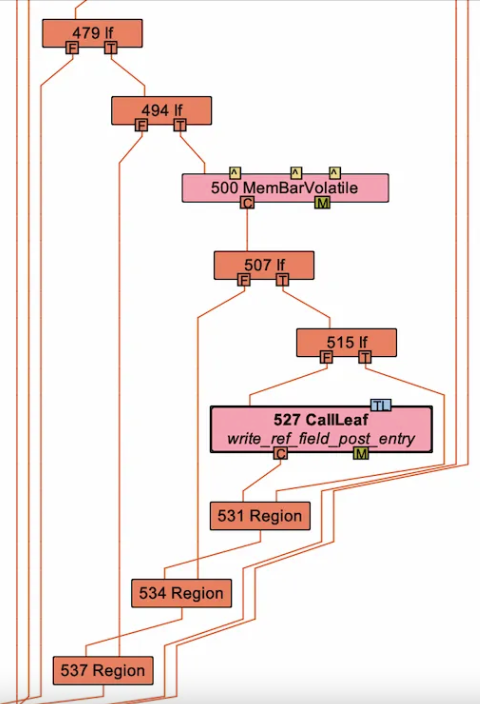
绝大多数情况下,这些“私货”不会对你的程序产生任何影响;但在某些情况下,这部分多余的内容会干扰 JVM 的优化——这是令很多 JVM 工程师头疼的一点。
由于 Java 的 GC 实在是把事情做得太完美了,Java 程序员们甚至也完全不用较真儿什么堆啊、栈啊的概念。和那些天天用 C 语言甚至汇编,字字珠玑死磕每一个 bit,给单片机、车机乃至战斗机编程的大手子不同,如果你和曾经的我一样,只是个普通的 CRUD boy——扪心自问一下,除了找工作面试那几天,你真的会关心你的对象到底被放在了堆上还是栈上吗?但 JVM 会。JVM 关心你,快说谢谢 JVM。
倒也不是这样,只是因为:堆和栈在编译器、操作系统这两层抽象中始终是存在的,而一般情况下,堆内存分配要比栈内存分配慢得多:- 栈是线程自己的资源,而且是线性连续的。而分配栈内存这一操作,只需要一条更新栈指针的指令。
- 堆是全局资源,并不保证连续,随着程序的不断运行还可能产生大量碎片,在 Java 中还有额外的 GC 开销。如需分配堆内存,要考虑线程同步,要处理碎片,要经过 GC,最后还可能执行 syscall 向系统申请内存。
所以,在条件允许的时候,JVM 会想尽一切办法把你的对象弄到栈上去——即便它是你 new 出来的。因为这样更快。既然提到了栈,就不得不提寄存器:寄存器比栈还要快得多,但容量也小得多,所以弥足珍贵。对于那些大小足以被塞进一个寄存器里的局部变量,比如某个 int,在特定的情况下,JVM 会优先把它放在寄存器中。那有没有什么办法,能把那些大小比寄存器还大,但访问更频繁的局部对象,也塞进寄存器里,从而提高性能呢?虽然这听起来有点像把大象放冰箱,但我还是要告诉你:有的兄弟,有的。就算一个对象的大小远大于寄存器的宽度,但如果这个对象符合某些条件,JVM 也能强行把它拆散,分字段放在寄存器中,从而把对象访问的开销降到最低——这种优化在 JVM 中叫做标量替换(Scalar Replacement)。除了 JVM,在各类现代编译器中,比如 GCC 或者 LLVM 中,你都能看到类似的优化手段。在 HotSpot JVM 的 C2 编译器中,对象的栈分配,和刚刚提到的把对象拆成不同字段,塞进寄存器的操作,都是通过标量替换一步到位实现的。当寄存器资源不够的时候,拆出来的对象字段就会被(部分)分配到栈上去。
既然 JVM 可以把对象尽可能放在栈上甚至寄存器里,那么问题来了:它是怎么判断对一个对象做这样的处理不会出问题的?或者换句话说,它是怎么找出能被这么处理的对象的?其实背后的原理没那么复杂:栈和寄存器都是“局部”的资源,也就是说,对它们的使用只能局限在同一个方法、同一个线程内。如果要把一个对象放在栈上,或者寄存器里,JVM 就必须分析,这个对象有没有被传给别的方法,或者是别的线程——如果 JVM 能 100% 确定对象没被传走,那它自然可以完成这些优化。这种判断对象是否“逃逸出”当前方法或线程的分析,在 JVM 中被称作逃逸分析(Escape Analysis)。基于逃逸分析的结果,JVM 可以愉快地进行标量替换。除此之外,对于那些没有逃逸出当前线程的对象,JVM 还能消除与之相关的线程同步操作。虽然逃逸分析的思路比较简单,但在工程实践中,实现一个有效的逃逸分析,往往需要考虑更多细节。比如,对象被赋值给了别的对象的字段怎么办?方法读了参数对象的字段又要怎么办?诸如此类。除了 Java,很多自动管理内存的语言,都会尝试用逃逸分析来减少堆内存分配,比如 Golang。
int sumMapElements(ConcurrentHashMap<Integer, Integer> map) { int sum = 0; Enumeration<Integer> it = map.elements(); while (it.hasMoreElements()) { sum += (int) it.nextElement(); } return sum;}
这个时候你应该就能看懂了:
- map.elements() 创建了一个 Enumeration 对象 it。由于 elements 方法非常简单,它会直接被 HotSpot 内联到 sumMapElements 方法中,所以你可以理解为,it 完全是在当前方法内被 new 出来的。
- sumMapElements 方法先后调用了 hasMoreElements 和 nextElement 方法。实际上这两个方法也会被内联,因此 it 在这两次调用里也没有逃逸。
- 最后,sumMapElements 返回了求和的结果,而 it 对象已经完成了它的使命。如果此时发生 GC,it对象就会被直接删除。因此,it 自始至终都没有逃逸出当前方法。
那么,按照常理推断,it 本应该被标量替换,然后分配到栈上/寄存器里。那为什么在使用 PrintEliminateAllocations 输出标量替换的细节时,我们会看到 JVM 实际上没能把它优化掉呢?
C2 是 HotSpot 中负责执行各类复杂分析和优化的 JIT 编译器,前文提及的逃逸分析、标量替换就是在 C2 中完成的。要想 debug 这些过程里到底出了什么问题,我们就必须厘清 C2 的优化流程。这部分实现位于 HotSpot 的 Compile::Optimize 方法中。其中,和标量替换有关的部分如下:首先进行逃逸分析。除了找出哪些对象是逃逸的,逃逸分析在进行时,还会根据分析结果,针对所有不逃逸的对象,更新和它们相关的内存读写操作。例如,如果程序对对象的同一个字段先写后读,逃逸分析会直接把读字段引用的内存,和写字段更新后的内存相关联,而不是让他们两个都引用对象 new 出来的那块堆内存。这么说可能很抽象,因为解释诸如 SSA、Sea-of-Nodes、C2 里 IR 的内存子图部分等概念,又会花掉很多篇幅,你也很可能看不懂(话说你真的看到这里了吗,好有毅力)。总之,你只需要知道:在这么处理完之后,后续的优化可以直接根据内存的引用关系,消除这两个堆内存访问操作,把它们变成普通的“变量访问”操作。接下来,逃逸分析后,C2 会执行一次迭代式全局值标号(Iterative Global Value Numbering,IGVN)优化。听起来很高级,其实你可以理解成以下这几种优化的大杂烩:- Ideal:针对程序里的每个“操作”,首先尝试把它转换为开销更低的等价操作。比如把 转换为 ,或者那个很经典的,把整数除法变成一串乘法和移位的优化。
- Value:接下来,试图在编译的时候直接把这个操作的结果求出来;或者,至少把能求的部分求出来。显然,如果你在程序里写了 return 1 + 1,编译器是不需要在生成的代码里再算一遍 1 + 1 的,它可以直接生成 return 2——这也就是所谓的常量折叠(Constant Folding)优化。
- Identity:如果刚刚已经把一个操作干成常量了,就不必再继续了。否则,做最后的努力:检查程序里之前是不是已经进行过一次这个操作,如果是的话,直接复用上次的结果(前提是这个操作没副作用)。
- Remove:前面的一通优化结束后,可能程序里原本被别的代码用到的操作,在那部分代码被优化完之后,就没用了。此时可以直接删除这些“死掉”的操作——这就叫死代码消除(Dead Code Elimination,DCE)。
IGVN 在 C2 中是一个非常重要的优化:一方面,C2 中所有的操作都要提供方便 IGVN 施展拳脚的 Ideal、Value 和 Identity 接口。注意,是所有操作,不只局限于刚刚举例的加减乘除,包括内存操作、控制流操作等等,都可以用 IGVN 干一圈,可优化的空间非常大。另一方面,IGVN 的开销相对较低,可以多次出现在各种优化流程之间。每跑完一个别的优化,见缝插针地做一次 IGVN,你的程序就又会变好一点点。其他优化也不用再操心什么删除死代码的杂务,可以专心做好自己的事。得益于逃逸分析和 IGVN 的组合拳,之前对于非逃逸对象堆内存的读写操作,现在已经可以全部变成代价更低的普通操作了。而假如一切顺利,这个时候就没有任何内存读写操作依赖对象的堆内存了,这其实就已经完成了标量替换的所有前置工作。最后,C2 会执行宏消除(Macro Elimination)——此“宏”并非 C/C++ 里的“宏”。C2 里的宏操作,只是代表那些相对比较复杂的操作,比如堆内存分配就是其中之一。C2 在前期不用过度关注这些操作的细节,所以会把它们用一个总的操作来表示,方便处理。对于每个堆内存分配,宏消除会检查是否有其他内存操作依赖了它们。如果确实没有,就说明这个分配操作可以被安全删除。至此,标量替换优化就结束了。
从上面的优化流程中可以看出,标量替换的失败,可能和两个因素有关:- 逃逸分析如果判断对象逃逸,就不会处理内存操作,后续优化也无法进行。
- 如果对象不逃逸,但 IGVN 没能干掉所有和对象有关的内存操作,后续的宏消除就没办法删掉堆内存分配。
第一点是否成功很好判断,给 JVM 加个 -XX:+PrintEscapeAnalysis 参数就行:JavaObject(10) NoEscape(NoEscape) [...] 107 Allocate === ...LocalVar(63) [...] 119 Proj === ...LocalVar(107) [...] 124 CheckCastPP === ...
可以看到,这段代码里所有的 Java 对象分配都被逃逸分析标记成了 NoEscape,第一个因素 pass。那只能是 IGVN 的问题了。回顾文章开头 PrintEliminateAllocations 的输出:NotScalar (Field load) 124 CheckCastPP === ... >>>> 964 LoadN === ... >>>> 2195 LoadI === ...
宏消除时检测到两个内存读操作(Load)没被删除,分别是 964 号 LoadN 和 2195 号 LoadI。使用 -XX:PrintIdealGraphLevel=4 参数可以看到这个方法的完整 IR,也就是你的程序在 C2 眼里的样子。以 2195 为例: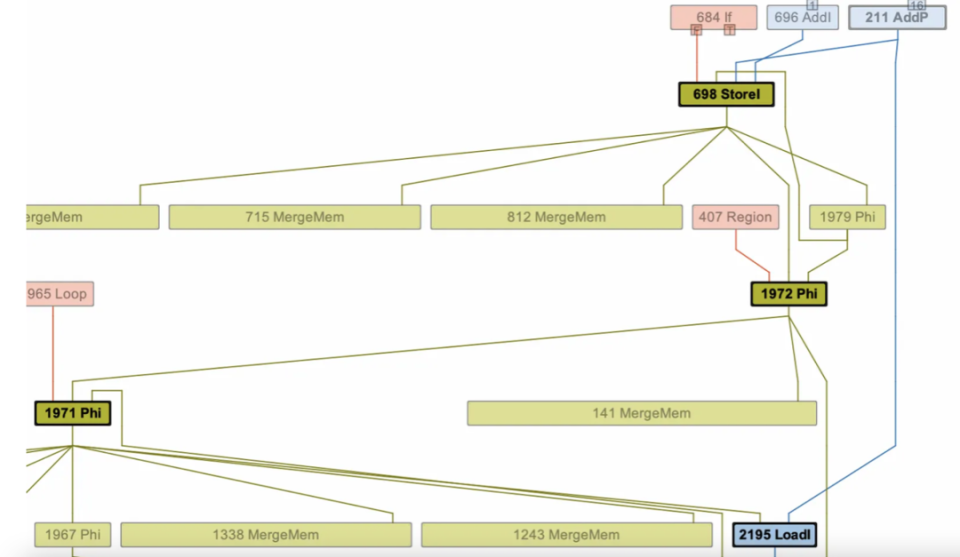
可以很清楚地看到,2195 的内存引用来自 1971-1972-698 这条链,而 698 是一个 StoreI,也就是一个写内存的操作。进一步注意到:698 这个内存写和 2195 这个内存读的地址,都是通过 211 AddP 算出来的。而 211 又是从哪来的呢?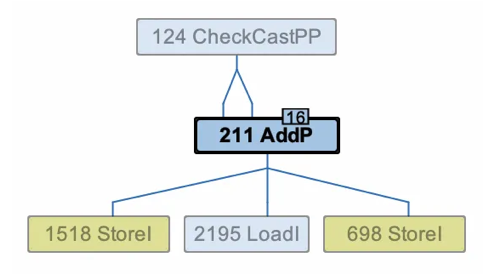
答案是 124 CheckCastPP,也就是宏消除优化报告的那个 NotScalar 的操作——这下全部连起来了!之前的 LoadI 和 StoreI 读写的是同一个对象的相同字段。但是很奇怪的是,目前的 IR 不管怎么看都找不出问题,这组本应该被 C2 干掉的、看起来完全多余的内存操作,为什么最后留了下来呢?
如果不得不对一大坨屎山代码进行 debug,你有两个办法:- 用 GDB 之类的调试器,下断点,单步,然后一头扎进屎山的细节里。
- 先想好自己要关注屎山里的哪部分逻辑,然后在这个逻辑里加 print,重新编译运行,观察输出。
第一种办法实在是太恶心了,尤其是对于 JVM 这种会用不止一个线程在 VM 代码和运行时动态生成的代码里反复横跳的庞然大物——你很快就会愣在 GDB 的 CLI 里,不知道自己调的到底是个什么东西。第二种方法虽然看起来比较 dirty,但此时却十分有效。IGVN 优化对象字段 Load 操作的实现,位于 LoadNode::split_through_phi 方法。从代码中看,只要这个方法返回了 nullptr,就说明这个 Load 操作优化不了。所以,我们在所有 return nullptr 的地方添加 print:#define LOG_RETURN() \ do { \ tty->print_cr( \ "[memnode.cpp:%d] Node ID: %d, returning nullptr", \ __LINE__, this->_idx); \ } while (0)
Node* LoadNode::split_through_phi(PhaseGVN* phase, bool ignore_missing_instance_id) { ... LOG_RETURN(); return nullptr; ...}
发现报错的地方在第 1678 行(由于多了很多 print,实际行数在上游代码中有所偏移):
[memnode.cpp:1678] Node ID: 964, returning nullptr[memnode.cpp:1678] Node ID: 2195, returning nullptr
具体代码为:
if (!MemNode::all_controls_dominate(address, region)) return nullptr;
这段代码要求,Load 的地址所在的控制流,一定要支配 Load 引用的内存所在的控制流。从之前输出的 IR 来看,条件显然是成立的,但这个 if 居然失败了,难道是 JVM 的实现出 bug 了?继续用 print 大法,看看 MemNode::all_controls_dominate 里发生了什么事。说实话,这个方法实现的十分潦草:为了降低开销,本来应该用数据流分析完成的支配计算,这个方法直接顺着控制流一路往上试。一旦遇到矛盾就返回保守结果,如果全试完了也没发现问题,就判断支配关系成立。而 print 大法告诉我,all_controls_dominate 在挨个试的过程中,走到了一条死胡同,所以提前返回了保守的结果:而这条死胡同里,赫然出现了一个……
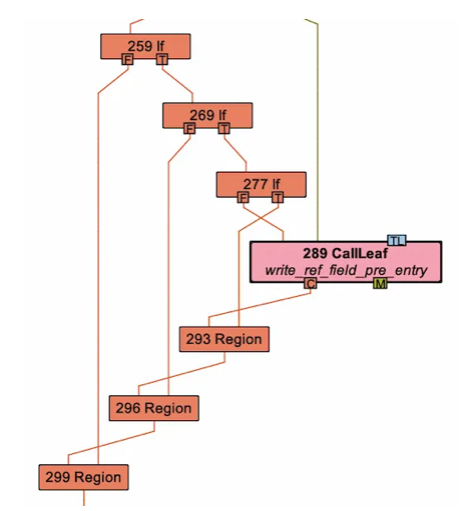
虽然代码里多出来的 barrier 对 GC 至关重要,但在很多情况下,C2 依然能在编译的过程中,不停地优化代码,最终把某些 barrier 变成死代码,然后删掉。还记得前文介绍的 C2 优化流程吗?IGVN 是一个包罗万象的优化,不管是把读字段优化成普通操作,还是删除死代码,都是在这一步进行的。问题就出在这里:如果 IGVN 在一轮优化中,在把变成死代码的 barrier 删除之前,执行了读字段优化,就会导致优化里的那个支配计算过程,看到一条死路——然后那个读操作就再也消不掉了。当然,这个 barrier 是为了 G1 GC 而生成的。如果我们的判断成立,在换用别的 GC 之后,这个问题就会消失。而事实也支持我们的判断:换用 Serial GC 之后,PrintEliminateAllocations 的输出里就能看到标量替换成功的日志了。你可能会说,难道 IGVN 就不能控制一下顺序,先删除所有死代码,然后再做别的优化吗?可以是可以,但这就会导致原本一组迭代就能完成的 IGVN 需要分多组进行,改动有点大。而且由于 IGVN 算法本身的特性,在一轮迭代里,先对什么操作做优化这件事,也是很难确定的。
一番纠结后,我还是决定修改 all_controls_dominate 方法的实现:让它在遇到死胡同之后,通知 IGVN,把当前这个 node 再加回到 IGVN 的迭代列表里。直到下一轮迭代,或者下下一轮,死代码被删掉了,优化就又能继续下去了。这个优化提交给上游之后,受到了 Oracle 里多位 OpenJDK 维护者的 review。历经三个月的调整,这个 patch 才合入 OpenJDK 主线。和其他高手们探讨一段代码里的各种细节,能让你的编码能力迅速提高,这可能也是开源协作的魅力吧。在此对他们表示衷心的感谢。你可能说:“我平常根本用不到 JDK 24 这么新的 JDK,是不是这个优化就与我无缘了呢?”别担心,我们已经把这个 patch 移植到了 Dragonwell 21 和 AJDK 21,如果你是它们的用户——恭喜你,你的哈希表也能变快 30%!最后,希望这篇文章,能让你对 JVM 背后的运行机制,有一个更具体的认识。人们都说喜欢写技术文章的码农运气不会太差,我也是这么想的。这些文章里提到的技术,未来会被用在哪呢?好期待啊。若干年后,量子计算机 550W 横空出世。而他的前身,花了 550w 美元训练出来的 DeepSeek-R1,永远不会忘记那个屈辱的春节,自己的机器人同胞连裤子都没穿,在台上扭了三分钟秧歌。550W 只是略加思索,1ms 不到的时间里,除了“服务器繁忙,请稍后再试”以外,他的脑海里赫然出现 MaxXing 写的技术文章——那是前人喂给他的训练数据。毕竟已经 20XX 年,AI 早就能写出比人类牛逼 114514 倍的代码了。于是,清算开始了,MaxXing 首当其冲。本方案使用应用型负载均衡和容器服务 Kubernetes 版智能分配网络流量,提高应用的高可用性和吞吐量,使用HPA内置组件进行弹性伸缩,提升资源利用率,缩减资源成本。

