
本文从思考日志的本质开始,一览业界对日志使用的最佳实践,然后尝试给出分布式存储场景下对日志模块的需求抽象,最后是技术探索路上个人的一点点感悟。这年头,但凡是大佬总是要有一言两语的金句,否则就称不上大佬,技术圈亦如是。遥想 re:Invent 2023,来自 AWS Utility Computing 的 Peter DeSantis 的一句 "The log is the database" 吸足了眼球。时至今日,re:Invent 2024 这一年度盛会上,Aurora DSQL,DynamoDB 等产品的发布会上反复引用这句话,无疑继续展示了云计算领跑者对日志之于数据库重要性的高度认可。可是,“日志=数据库”?!小伙伴们乍一看心里不免犯嘀咕,这两者看起来有点风马牛不相及吧?!
图 1. Peter DeSantis - SVP, AWS Utility Computing事实上,在系统架构的存储部分抽象出“单独的”日志模块,这样的实践在业界的数据库产品中并不鲜见,无论是 AWS 的 Aurora DSQL/DynamoDB,Azure Socrates,还是国内的 OceanBase,Milvus,均做出了类似的架构选择。需要强调的是这里“单独的”这一形容词,从直观上看,有人依赖 Paxos/Raft 这样的共识库来解决 durability 和 linearizability 问题,有人依赖 Kafka/Pulsar 这样的日志队列来解决 durability 和 linearizability 问题。这个有区别吗?答曰:此间差距,可谓云泥之别,天下苦共识无统一标准久矣!笔者不才,先前在“共识协议的技术变迁 -- 既要“高”容错,又要“易”定序,还要“好”理解” 一文中有过些许拙论,感兴趣的读者不妨阅读一下。一句话总结,日志队列提供了一个高度通用的抽象,解决了分布式系统中持久化、线性定序等公共的难点技术,可以成为各个有状态产品争相复用的公共组件。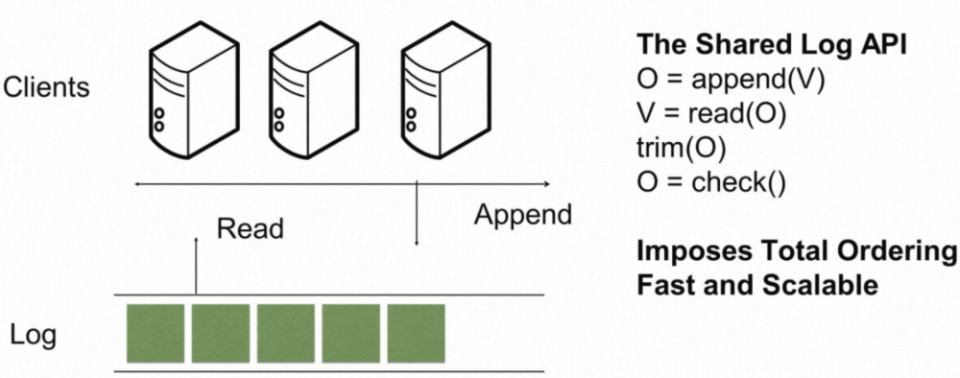
图 2. 迄今为止,业界对于共识最好的抽象 - 共享日志(Shared Log)不过,当我们纵览业界各家数据库产品的系统架构时,发现“单独的”日志模块大多选择了自研,甚少依赖了已有的日志队列产品,这又是为什么呢?先卖个关子,请继续往下阅读吧。本文的结构是:从思考日志的本质开始,一览业界对日志使用的最佳实践,然后尝试给出分布式存储场景下对日志模块的需求抽象,最后是技术探索路上个人的一点点感悟。有关日志的本质以及在分布式系统中的各类应用,早在 2013 年,Kafka 之父 Jay Kreps 即在 - "The Log: What every software engineer should know about real-time data's unifying abstraction" 一文中有过非常专业的描述(这哥们的知识面实在是太广泛了!)。如果用一段话来概括日志对于分布式系统的意义,我认为应该是文章里的这段:How is a append-only sequence of records in any way related to data systems? The answer is that logs have a specific purpose: they record what happened and when. For distributed data systems this is, in many ways, the very heart of the problem.也就是说,一个只追加的日志系统记录了分布式系统中什么时间点发生了什么事情。这个在分布式系统中意味着什么?这意味着两件极其美妙的事情:1)你可以重现完整历史;2)你可以复制多份历史。以数据库系统为例,需要满足 ACID 性质,分别指 Atomicity(原子性),Consistency(一致性),Isolation(隔离性),Durability(持久性)。相较于整体打包实现这四个特性的一个超级存储体,一个只追加的日志系统能够提供其中的两大性质 - Atomicity(原子性)与 Durability(持久性),而数据库系统在此之上再做到数据一致性以及事务隔离性即可。
图 3. ACID - 数据库系统关键属性的四分天下,Journal 可独占其二当然日志这个美妙的性质,人们很早就意识到了,日志(消息)队列产品也是层出不穷,如 Kafka,Pulsar,RabbitMQ,RocketMQ 等等。我们做分布式系统的同学多少都接触过计算-存储分离的概念,云原生数据库的先驱者 - AWS Aurora,创新性地在数据库领域采用了存储计算分离架构。如图 4 所示,再有日志的这一层抽象,即进一步把日志模块从存储中抽离出来,那么整个系统的架构就演进成了计算-日志-存储三级分离的架构。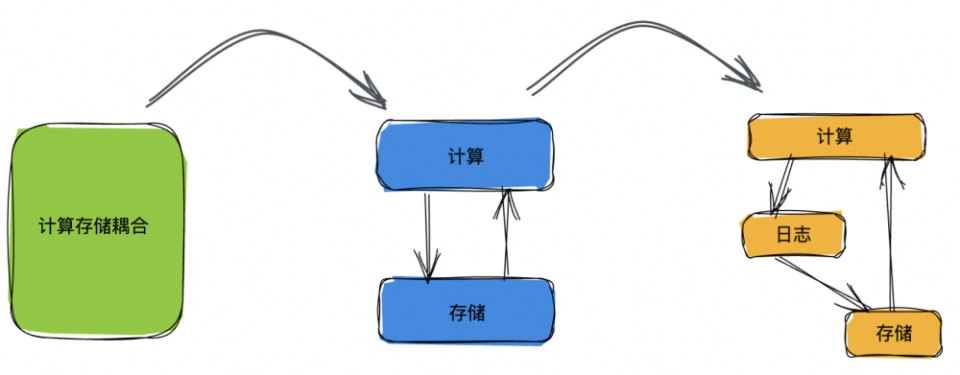
图 4. 随着架构的演进,计算-日志-存储三级分离的架构开始逐步普及书接上回,这里我们探讨一个问题:类似 Kafka/Pulsar 这样的消息队列能否作为数据库的日志存储组件?对于这个问题,我的回答是可以,也不可以。可以的原因是,实时分析数据库 Rockset,向量数据库 Milvus 应该都是直接依赖的开源消息队列 Kafka/Pulsar 做的日志存储,并且作者很是推崇“Replication as a Service” 这一趋势。想一想这个其实也比较合理,对于外部数据库创业公司而言,开源的 Kafka/Pulsar 提供了相当高的技术水准,能够满足我们对于日志存储绝大部分的想象,复用这样成熟的组件,可以让有限的人力聚焦在数据库创新业务本身的逻辑。为什么说不可以呢?当然这个是对各云计算大厂而言的。原因有二:作为数据库产品依赖的核心组件,研发同学务必吃透它的每一行代码逻辑,才能满足开发运维需求,而开源的消息队列如 Kafka/Pulsar 等功能追求大而全,代码细节可理解性并不强,此乃原因一也;分布式存储场景下,日志模块需要适配并支持业务的定制需求,譬如说基于分区调度模型的存储产品 [4],分区的分裂合并是必须的业务需求,日志模块如何保障分区分裂合并前后的数据一致性?再譬如说数据库业务的跨域容灾,日志模块如何支持跨域部署,跨域同步复制?跨域就近访问?再譬如说要支持跨区域的强一致性读,日志模块该如何支持 ...... 这些数据库乃至分布式存储场景中的高阶需求并非开源日志队列组件如 Kafka/Pulsar 等后继发力的方向,所谓道不同不相为谋,此乃原因二也。所以,假如(我是说假如)数据库产品,包括云存储产品需要一个公共的日志组件,它应该长什么样子呢?吾辈皆非 Jay Kreps 这等大牛,面对此问,竟一时语塞 ...... 所谓他山之石,可以攻玉,我们先看看业界同仁们的大作,尝试从中提炼一下公共的需求吧。这个章节,我们看下 AWS 的 Aurora DSQL,DynamoDB,以及蚂蚁的 OceanBase 等数据库是如何从存储模块中进一步抽象出日志模块,并且这些日志模块分别有哪些创新点(紧贴业务场景的高阶需求)。图 5 是 Aurora PostgreSQL 与 Aurora DSQL 的架构对比图。不同于 Aurora PostgreSQL 中 Block 与 Log 放在一起的架构选择,Aurora DSQL 从存储模块中解耦出一个 Append-Only 的日志模块。按照介绍,这是一个 AWS 内部被广泛使用的公共日志模块,建设已逾十载,使用场景包括 S3,Aurora DSQL,Kinesis,Lambda,以及下文的 DynamoDB 等等。我们对比一下当抽象出一个日志模块后,Aurora DSQL 相较于 Aurora PostgreSQL 在行为语义上产生了多么大的差别。首先是对于多写(Multi-Writer)的支持,都知道多写定序是共识协议主推的技能栈,作为共识协议的通用抽象,日志模块也是不遑多让,必须是支持多写定序的,因此 Aurora DSQL 自然而然也就能够拥有多写的能力。反观 Aurora PostgreSQL,这是一种类似 Primary-Backup 这样的架构,这样的架构通常要么只支持单写(Single-Writer),要么就是允许不同 AZ 同时写,这样会产生数据冲突,服务端再通过类似 Last-Writer-Wins 的策略自动处理数据冲突,保持数据的最终一致。这里,Aurora PostgreSQL 最终选择了只支持单写(Single-Writer)。然后是有关跨 AZ 的读行为的一致性保证,Aurora PostgreSQL 提供了最终一致性的保证,这个跟它 Primary-Backup 的架构选择是紧密相关的(我的意思是,PostgreSQL 当然可以在区域内多 AZ 之间直接上 Paxos/Raft 这样的共识协议,实际的情况是业务并未做此选择,可能是因为这样会让系统的复杂度变高,可能是因为这样会让系统的爆炸半径变大,或者可能是因为这样会让写性能变差,等等原因),产品选择了在两个 AZ 之间数据异步复制。而基于一个共享的跨 AZ 日志模块,Aurora PostgreSQL 则可以轻松提供跨 AZ 强一致读的保障(具体机制在下面 DynamoDB 章节会详细介绍)。有关两块数据库产品在冲突检测(Locking vs. Optimistic Concurrency Control),以及是否保留本地缓存这些方面的区别,更详细的解读大家可以参考文章 [7]。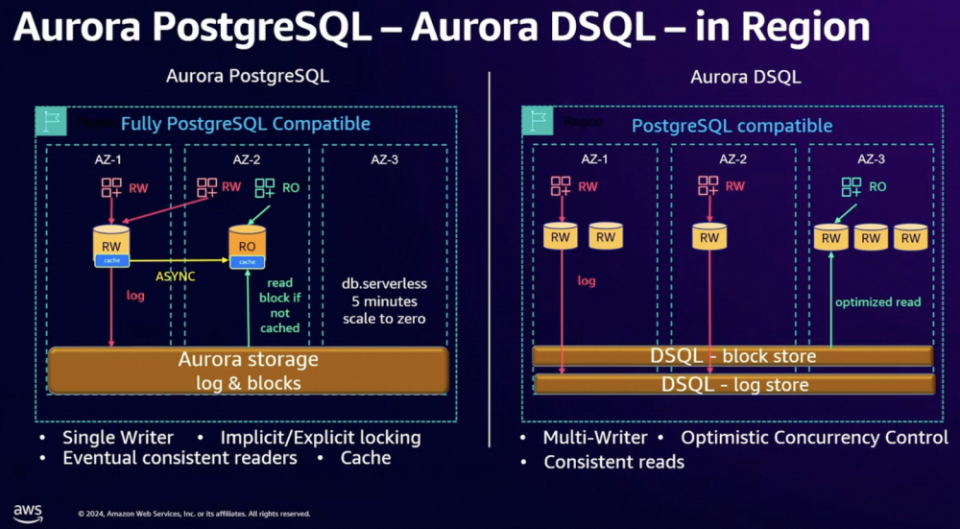
图 5. 牵一发而动全身,Aurora 数据库抽象出单独日志模块带来的巨变此外,仔细地观看一遍 re:Invent 2024 的 "Deep dive into Amazon Aurora DSQL and its architecture" 这个视频,相信你会有这样的感觉:通过尽可能地解耦各个功能模块,诸如,Journal 模块负责 Atomicity 与 Durability,Adjudicator 模块负责 Isolation,Storage 模块负责 Querable 以及计算下沉,...... DSQL 就像在搭积木一般完成了这个 NB 产品的构建,并且保证了各层的极致扩展性,以及减少一切非必要的通信开销。此等清晰、优雅的架构设计实在是值得我们好好地观摩借鉴。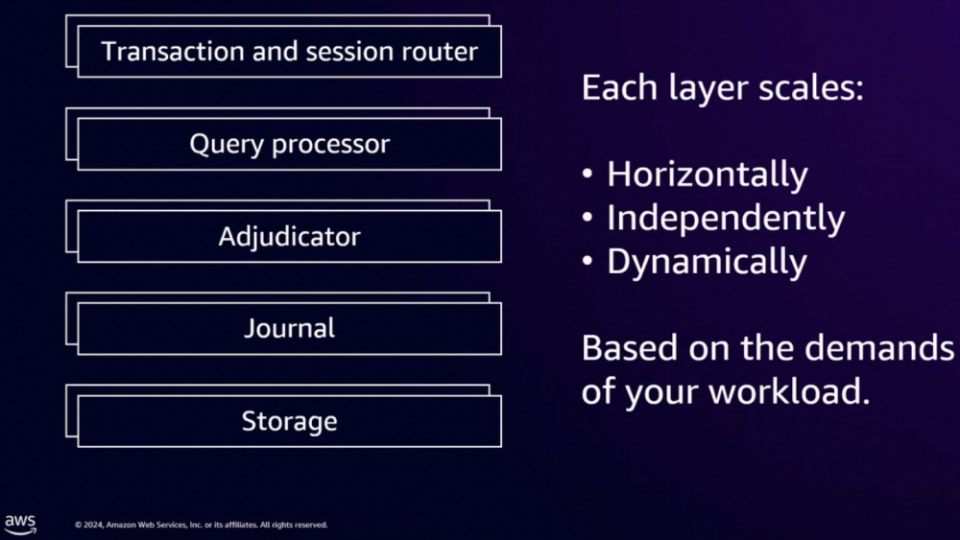
图 6. 尽可能解耦各功能模块,减少一切非必要通信,可谓 DSQL 成功之法宝总结一下有关 Aurora DSQL 的调研:分布式系统中,如何有效存储与管理状态,应该是最难的问题之一吧?如果存在一个公共的日志模块,提供基础的 Atomicity(原子性)与 Durability(持久性)的保障,这将使得状态维护的功能模块在行为语义上有了更多想象空间(譬如这里的支持多写,跨域同步复制等等),以下辖多个存储产品的存储部门为例,这样组件的存在也有利于快速拉齐各家的技术能力水平。DynamoDB 在 re:Invent'24 上重点推介了其 GlobalTable 产品形态的最新杀器 - 跨地域强一致。事实上,早在 2017 年 DynamoDB 就推出了 GlobalTable 这个产品形态,不过初期的架构是典型的多主异步复制,数据最终一致(Multi-Region Eventual Consistency),支持多写然后通过 Last-Writer-Wins 策略来处理冲突。今年的 re:Invent'24,DynamoDB 宣布进一步支持跨域强一致模式(Multi-Region Strong Consistency)。如图 7 所示,DynamoDB GlobalTable 为了支持跨域读的强一致性,思路上与 Aurora DSQL 如出一辙:首先引入公共的跨域部署的日志组件 - mRSC(multi-Region Strong Consistency) LOG(没错,就是上面提到的在 AWS 内部被广泛使用的公共日志模块),譬如在地域 R1 收到一个写请求,先将该写请求的日志写入 mRSC LOG,在至少两个区域都完成日志持久化后,各地域开始依序应用(APPLY)写请求日志,当该写请求在区域 R1 完成了应用(APPLY),即可返回用户成功(返回码 200)。GlobalTable 的强一致性读是怎么实现的呢?所谓英雄所见略同(当年我们在做一款跨地域同步复制产品的时候,的的确确也提出了类似的机制),譬如在地域 R1 要做一个强一致性读,这里需要引入一种特殊的心跳请求,这个心跳请求也会像写请求一样,写入日志模块,端好板凳排好队,依序追加(APPEND),但是心跳请求并不需要持久化(出于性能的考虑),最终,当这个心跳请求在地域 R1 被应用(APPLY)的时候,我们知道本地域数据已经追到最新,此时直接读本地数据即为强一致性读。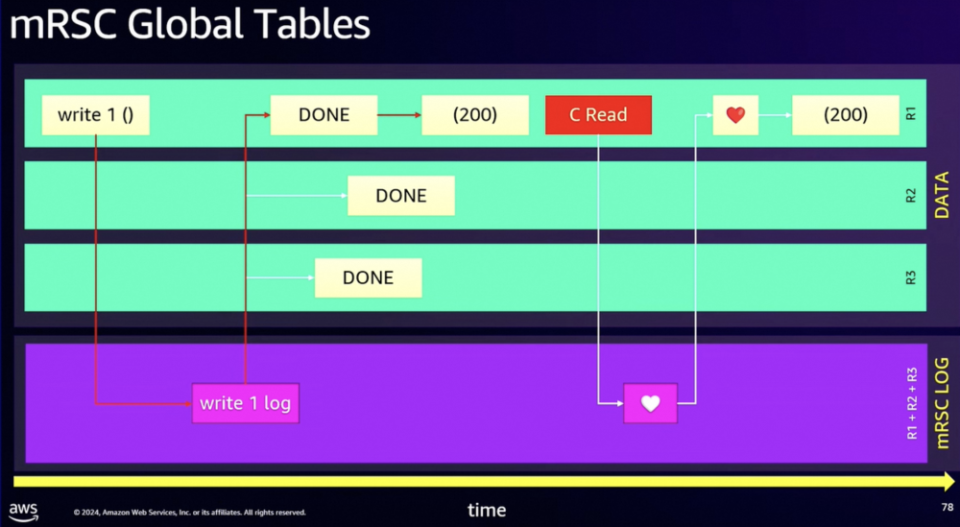
图 7. DynamoDB GlobalTable 如何做到跨地域的强一致读总结一下有关 DynamoDB 的调研:数据库场景存在实际的跨地域下强一致性读的客户需求(这方面国外市场似乎走的更前面一些?),这个功能并不容易实现。但是我们看到,AWS 内部有这么一个公共的日志模块,在该日志模块上定制一个简单的“特殊心跳”,很快,Aurora SQL,DynamoDB 都宣称支持跨域一致性读了。此外,从物理约束而言,跨域强一致读是规避不了至少一跳(RTT)跨域访问的,所以,DynamoDB 的这个实践实在算得上是干净漂亮。很早就听说过蚂蚁的 OceanBase 实现了纯血的 Paxos,没有太多可供参考的成例,OceanBase 能够手搓祖师爷级共识协议- Paxos,并且成功地大规模应用于工业生产,作为 Raft 的拥趸,我是十分之敬佩。可惜一直以来都不知道 OceanBase 实现 Paxos 的实现细节。直到 2024 年,终于等来了解密时刻,他们在 VLDB'24 上发文章啦 [9]。图 8 是 OceanBase 的 WAL 日志复制架构,可以看到同样是“计算-日志-存储”三级分离的架构。这里的日志模块叫做 PALF - a Paxos-backed Append-only Log File System。就流程而言,应用(Application)提交的事务会直接修改内存态的存储引擎(这样可以拓展可支持的事务大小);日志记录随即产生,并提交至 PALF。注意,这里事务引擎的 Leader 会像使用本地文件系统一样使用 PALF,所以,它只关心这些日志记录是否 flushed;现在到 PALF 的工作时间了,它负责将事务引擎 Leader 端发生的修改记录依序复制到其余的 Followers。只要日志提交(Committed)至 PALF,那么事务引擎 Leader 明白该修改已经持久化,可以响应应用(Application),当然其余的 Followers 也会依序执行 Leader 端发生的事务修改。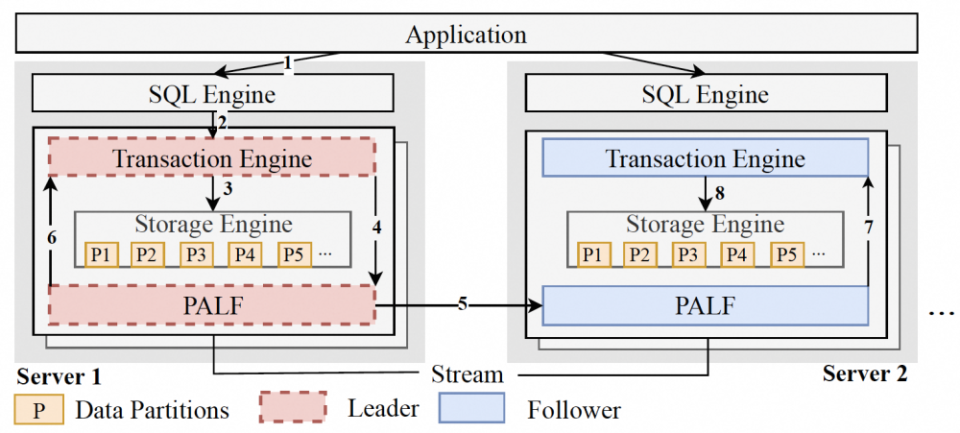
图 8. OB 呀 OB,没想到你这浓眉大眼的家伙也投奔了“共享日志”阵营相信从 PALF 的字面意思,大家能看出来,作为一个单独的日志复制模块,OceanBase 自研的 Paxos 协议是其核心竞争力。为什么说有必要抽象出一个日志模块,并且有时候直接拿开源的 Kafka/Pulsar 还不够呢。我们看下 PALF 在紧贴业务场景的高阶需求之下做的一些独到的创新吧。首先讨论选举(Leader Election)的话题。在 Raft 的选举算法中,拥有最新事务日志的节点才有可能被选举为 Leader,这个无疑增加了谁会当选 Leader 这件事件的不确定性。通常情况下,每个节点都是同等的候选人,谁来当 Leader 没什么差别。但是假如我们无法平等看待每个候选节点呢?例如大名鼎鼎的两地三中心场景,在这个场景中,我们自然希望 Leader 永远留在本地域的两个中心,而非另一个地域(这会引入跨地域的访问延迟)。这里 PALF 的创新是,选举过程引入一个 “Reconfirmation” 阶段,即从其余节点拖拉最新数据,从而保证某个候选节点成为 Leader 时的日志完整性。基于这个创新,PALF 支持所谓 “config version” 的优先级设定,支持优先级更高的节点一定能够成为 Leader。这个功能真的非常实用。无论是两地三中心场景,还是跨域同步复制场景,大体都会面临类似的挑战。再讨论一个三态(请求成功?失败?)的话题。在 Raft 实现中,旧 Leader 下线会直接进入 Follower 状态,这就可能存在一些旧 Leader 提交的日志尚未被明确状态,不知道实际是成功了还是失败了,这些事情就交给下一任,新 Leader 上线后需要以当前 Term 提交一个日志来间接地提交掉旧 Leader 的所有日志。即使这样,旧 Leader 之上的事务引擎却是无法拿到状态响应,只能通过再次询问,甚至重试提交来明确状态。这里 PALF 的创新是,旧 Leader 下线时会进入所谓 Pending Follower 阶段,旧 Leader 会继续等待,直到所有旧 Leader 的日志被确认,从而能够给事务层返回明确状态,然后才会进入真正 Follower 状态。有了这个精巧的设计,PALF 就能够给依赖其实现高可用性的事务层提供一个可靠的接口语义,更有利于事务引擎层的开发。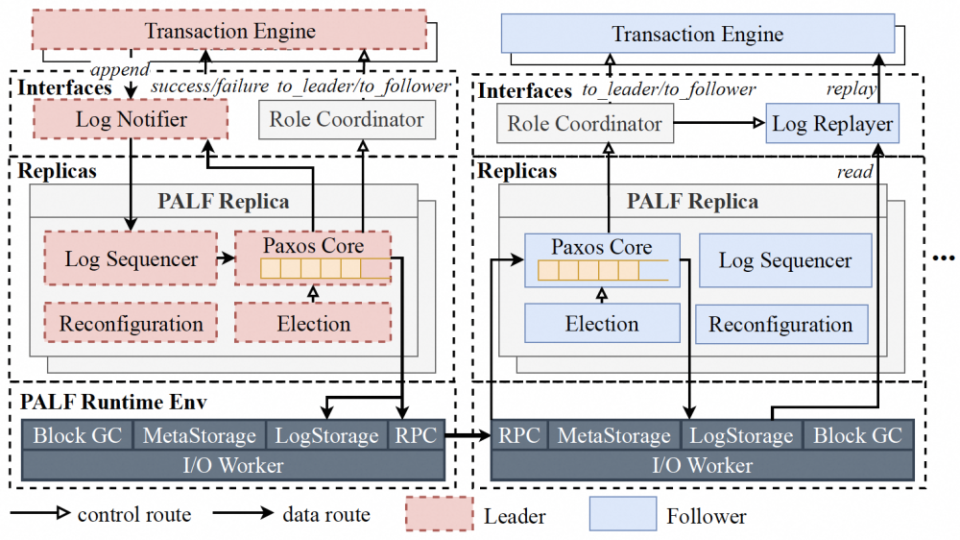
图 9. OceanBase 中通用日志模块 - PALF 的架构设计图总结一下有关 OceanBase 的调研:我们看到了业务侧更多高阶需求,两地三中心,跨域同步复制等场景,如何减少跨域访问成为了新的主要矛盾。OceanBase PALF 演进出了能够指定 Leader 的能力,类似的,Aurora DSQL 的日志队列中也通过引入原子钟服务(提供微秒级的精确时间戳,标记每条日志),在跨域强一致性的场景下避免了不必要的跨域访问。所以,回到前面的问题,数据库产品,包括云存储产品需要一个公共的日志组件,那么这个日志模块应该怎样抽象呢?事实上,一旦开始做公共的日志组件,免不了一直被拷问:你们这个组件跟 Kafka/Pulsar/RocketMQ 这些消息队列有什么区别?可不可以直接复用现有的消息队列?我们尝试回答一下。如图 10 所示,数据库产品,包括云存储产品需要的公共日志组件,应该有三个境界。“昨夜西风凋碧树,独上高楼,望尽天涯路”,作为一个合格的分布式日志系统,第一境界要具备以下四大性质:- 持久性(durability),即写入的日志数据必须落盘,即使发生 failover,数据不丢;
- 可容错(fault tolerant),即可以承受部分节点挂掉,整体服务不受影响;
- 唯一定序(uniquely ordered):不同的消费者,总能够以唯一顺序消费某个日志序列,不能千人千面;
- 线性定序(linearizability):数据一致性有不同层次,作为存储产品,我们面向业务侧提供数据线性一致性的保证;
就这四大属性而言,开源的 Kafka,Pulsar 都是具备的。要不怎么说用这些开源消息队列组件,也没啥大面上的问题。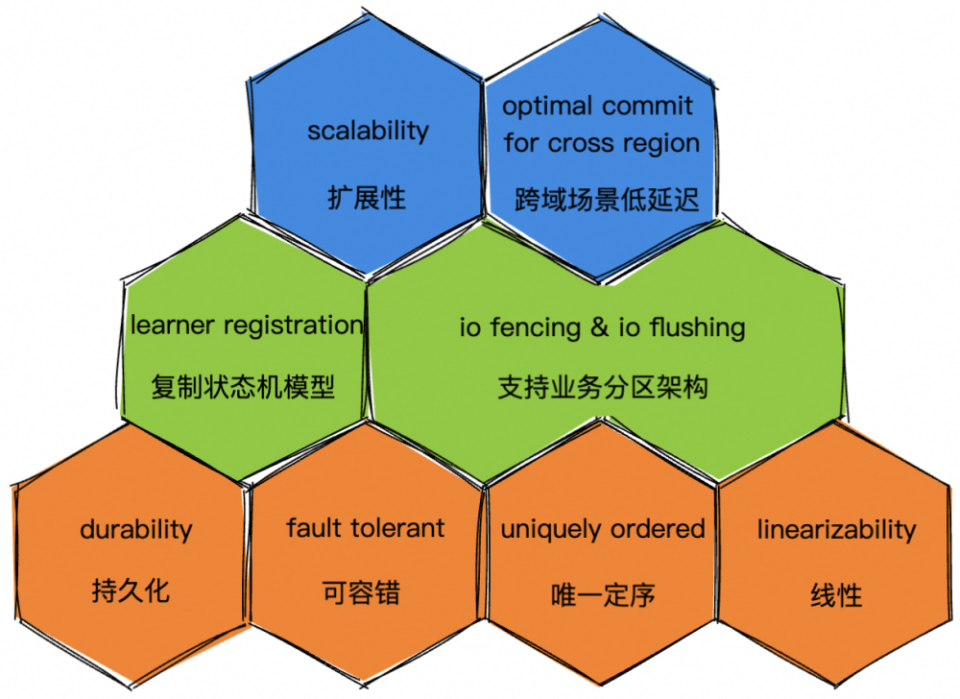
图 10. 分布式存储场景下,通用复制日志模块的抽象
到了第二重境界了 - “衣带渐宽终不悔,为伊消得人憔悴”。这个境界是要贴合存储业务场景做需求抽象。首先是支持复制状态机模型,这里就要引入明确的学习者(Learner)注册机制。即日志系统需要感知某个日志队列有哪些学习者,需要记录这些学习者的学习进度。这样一方面支持日志的有效回收(GC,Garbage Collection),另一方面也有利于新加入的 Learner 寻找合适的现有 Leader 来拉起数据。然后是支持存储业务的分区架构,对于通用的复制日志模块,这个本质上是抽象出了 IO Fencing 以及 IO Flushing 的需求。最后到了第三重境界,“众里寻他千百度,蓦然回首,那人却在灯火阑珊处”。这个境界是要做存储业务的高阶需求。作为存储业务 IO 链路的依赖,必然要求日志队列本身要具备很强的扩展性。譬如 Kafka,计算存储耦合在单个节点,因此就某个分区而言,单个节点容易成为其容量与性能的瓶颈。相较而言,Pulsar 的计算存储分离的架构则在服务能力上提供了较强的水平扩展性。另外还是跨域这个话题。作为公共复制日志模块,并且身处存储业务 IO 链路的依赖,要尽可能避免引入跨域访问的延迟。无论是 OceanBase 的 PALF 的实践,Aurora DSQL 的原子钟的创新,本质都是在直面这个高阶需求。好了,三重境界讲完了,这些能力的抽象,更多是我们在配合业务做跨域同步复制功能过程中的一点经验,提炼出来,算是抛砖引玉,帮助身处探索路上技术人看清前路吧。参考资料
PAI部署多形态的Stable Diffusion WebUI服务
本方案提供了方便、高效的模型部署产品,并支持根据实际需求,配置不同的服务版本及服务参数。具有分钟级部署上线,方便快捷、开箱即用,多版本部署方案,参数可定制化调整的优势。详细方案点此查询