作者:Kwindla Hultman Kramer等
OpenAI Realtime API 的「说明书」。
很多研究 ChatGPT 的人,在使用后不久就会开始捣鼓 ChatGPT API。它是 OpenAI 提供的开放程序接口,让开发者可以把业界最先进的大模型引入到自己的产品中,构建聊天机器人、虚拟助手等等。近一年来,依靠这套工具打造的热门 App 已有不少。Realme API 是 OpenAI 最新发布的 API 能力,它在今年 10 月 1 日推出,可帮助开发人员构建快速语音转语音的智能化体验。近日,在 OpenAI DevDay 新加坡站,来自 Daily.co 的工程师受邀演讲,介绍了基于 OpenAI 的能力构建语音 AI 智能体的方法。一直以来,该公司的工程师们一直在使用实时 API 搭建产品。在活动之后,演讲人发布了本篇博客,谈了谈构建 Pipecat 时的经验教训。博客地址:https://www.latent.space/p/realtime-api本篇博客的内容已通过 OpenAI 员工审核。Pipecat 是由 Daily 发起的开源项目,现在是一个实时 API 框架。对于想要构建大模型语音产品的人们来说,这篇内容可能包含你所需要的一切,从 24khz/G.711 音频、RTMP、HLS、WebRTC 的技术细节到中断 / VAD,再到成本、延迟、工具调用和上下文管理。(以下为博客原文,机器之心做了不改变原意的编译、整理。)首先,我们愿意分享一些在使用原始实时 API(无框架、无外部依赖)时积累的心得,特别是在准备新加坡 DevDay 演讲的过程中。标准的 OpenAI 参考应用包含了许多内置功能,我们尽量精简这些功能,专注于语音活动检测(VAD)和函数调用,从而打造了一个「简易实时控制台」演示。实际上,语音活动检测(VAD)并不总是完美无缺,而且演示语音应用时很少能在完全安静的环境下进行。因此,我们建议在演示中始终配备「静音」和「强制回复」按钮,正如我们的演示所示。此外,该演示还展示了如何简单添加和插入记忆,以及如何展示对话双方的记录。在我的大部分职业生涯中,我都在研究人与人之间对话的网络基础设施 —— 用于构建低延迟媒体流、视频通话和大数据协作环境等的工具。2023 年 3 月,GPT-4 还是一个纯文本模型。但为 GPT-4 开发语音模式相对容易。我整合了一个语音转文本系统,将语音输入转换成文本提示,然后将 GPT-4 的文本输出送入一个文本转语音的音频生成器中。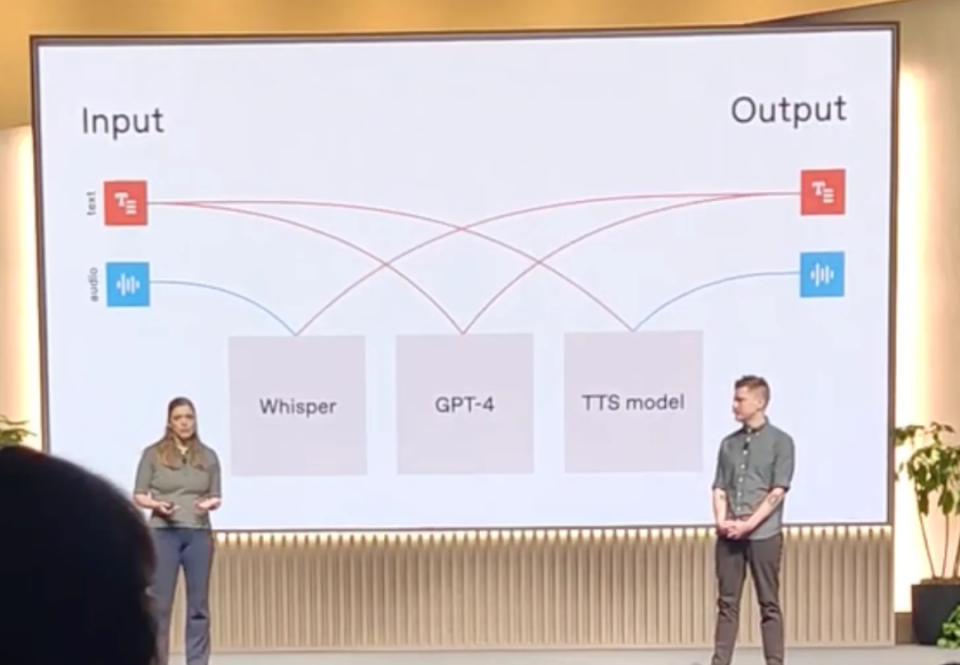 [语音输入] ➔ [ ASR ] ➔ [ GPT4 ] ➔ [ TTS ] ➔ [语音输出] —— 内容来自 DevDay Realtime API Talk:https://www.youtube.com/watch?v=mVR90WmA34U这种多模型 pipeline 方法并不新鲜。我们拨打电话客户支持热线时使用的「自然语言处理」系统就是这样工作的。新方法是 pipeline 核心的 GPT-4 大型语言模型。你可以用 GPT-4 进行真正的对话。很明显,那些较旧的 NLP 系统已经过时了。但显然,新的挑战也已出现。这个系统的延迟很长。GPT-4 需要一秒钟左右才能开始生成响应。STT 和 TTS 模型又增加了一两秒钟。有时 GPT-4 会偏离轨道。弄清楚如何检测这个问题,并把问题出现的几率降到最低,似乎是一件相当困难的事情。一些经典的 NLP 问题仍然存在,例如句尾端点(弄清楚 LLM 应该何时响应)和中断处理。GPT-4 擅长对话,但没有很好的方法与现有的后端系统集成。现有 TTS 模型的语音输出质量,一听就知道是机器人声。自 GPT-4 发布以来的 20 个月里,人工智能提升的速度令人惊叹。当前版本的 GPT-4 擅长遵循提示、专注于任务并减少了幻觉。函数调用和结构化数据输出是可靠的。模型响应迅速,我们拥有快速、价格合理且质量相当高的 TTS 模型。最新的 GPT-4 功能是原生音频输入和输出。GPT-4——升级版的 GPT-4o——现在有了自己的声音和耳朵!10 月 1 日,OpenAI 发布了一款低延迟、多模态 API,该 API 利用了 GPT-4o 出色的「语音到语音」功能。这个新的「实时 API」能够管理对话状态、实现短语端点(轮流检测)、提供双向音频流,并支持用户中断 LLM 的输出。使用此 API,最简单的处理 pipeline 如下所示:
[语音输入] ➔ [ ASR ] ➔ [ GPT4 ] ➔ [ TTS ] ➔ [语音输出] —— 内容来自 DevDay Realtime API Talk:https://www.youtube.com/watch?v=mVR90WmA34U这种多模型 pipeline 方法并不新鲜。我们拨打电话客户支持热线时使用的「自然语言处理」系统就是这样工作的。新方法是 pipeline 核心的 GPT-4 大型语言模型。你可以用 GPT-4 进行真正的对话。很明显,那些较旧的 NLP 系统已经过时了。但显然,新的挑战也已出现。这个系统的延迟很长。GPT-4 需要一秒钟左右才能开始生成响应。STT 和 TTS 模型又增加了一两秒钟。有时 GPT-4 会偏离轨道。弄清楚如何检测这个问题,并把问题出现的几率降到最低,似乎是一件相当困难的事情。一些经典的 NLP 问题仍然存在,例如句尾端点(弄清楚 LLM 应该何时响应)和中断处理。GPT-4 擅长对话,但没有很好的方法与现有的后端系统集成。现有 TTS 模型的语音输出质量,一听就知道是机器人声。自 GPT-4 发布以来的 20 个月里,人工智能提升的速度令人惊叹。当前版本的 GPT-4 擅长遵循提示、专注于任务并减少了幻觉。函数调用和结构化数据输出是可靠的。模型响应迅速,我们拥有快速、价格合理且质量相当高的 TTS 模型。最新的 GPT-4 功能是原生音频输入和输出。GPT-4——升级版的 GPT-4o——现在有了自己的声音和耳朵!10 月 1 日,OpenAI 发布了一款低延迟、多模态 API,该 API 利用了 GPT-4o 出色的「语音到语音」功能。这个新的「实时 API」能够管理对话状态、实现短语端点(轮流检测)、提供双向音频流,并支持用户中断 LLM 的输出。使用此 API,最简单的处理 pipeline 如下所示: [ 语音输入 ] ➔ [ GPT-4o ] ➔ [ 语音输出 ] 我一直在帮助客户、朋友和与我一起在开源项目上工作的人们使用 OpenAI Realtime API。使用这个新 API 与使用 OpenAI HTTP 推理 API 完全不同。新的 Realtime API 是有状态的。它在 WebSocket 连接之上定义了一个双向事件协议。最近,我写了关于 Realtime API 的优点、我认为还需要一篇博客来讲如何有效使用 Realtime API 。无论你是工程师还是开发者,都希望能从这篇博客找到一些有用的背景信息、代码片段,和可以节省你时间的具体细节。在适当的地方,我会提供链接到 Pipecat 的源代码和示例。Pipecat 是一个开源的、供应商中立的 Python 框架,专为实时、多模式 AI 代理和应用程序设计。它支持 GPT-4o 及其实时版本,以及超过 40 种其他 AI API 和服务,还涵盖了多种网络传输选项,包括 WebSockets、WebRTC、HTTP、SIP 以及 PSTN / 拨入 / 拨出等。Pipecat 还附带一个大型核心功能库,用于上下文管理、内容审核、用户状态管理、事件处理、脚本跟踪以及语音(和视频)代理的其他重要构建块。
[ 语音输入 ] ➔ [ GPT-4o ] ➔ [ 语音输出 ] 我一直在帮助客户、朋友和与我一起在开源项目上工作的人们使用 OpenAI Realtime API。使用这个新 API 与使用 OpenAI HTTP 推理 API 完全不同。新的 Realtime API 是有状态的。它在 WebSocket 连接之上定义了一个双向事件协议。最近,我写了关于 Realtime API 的优点、我认为还需要一篇博客来讲如何有效使用 Realtime API 。无论你是工程师还是开发者,都希望能从这篇博客找到一些有用的背景信息、代码片段,和可以节省你时间的具体细节。在适当的地方,我会提供链接到 Pipecat 的源代码和示例。Pipecat 是一个开源的、供应商中立的 Python 框架,专为实时、多模式 AI 代理和应用程序设计。它支持 GPT-4o 及其实时版本,以及超过 40 种其他 AI API 和服务,还涵盖了多种网络传输选项,包括 WebSockets、WebRTC、HTTP、SIP 以及 PSTN / 拨入 / 拨出等。Pipecat 还附带一个大型核心功能库,用于上下文管理、内容审核、用户状态管理、事件处理、脚本跟踪以及语音(和视频)代理的其他重要构建块。- 完整的 Pipecat OpenAI Realtime API 集成在这里:https://github.com/pipecat-ai/pipecat/tree/main/src/pipecat/services/openai_realtime_beta
- 这是一个使用 Realtime API 的单文件示例语音机器人:https://github.com/pipecat-ai/pipecat/blob/main/examples/foundational/19-openai-realtime-beta.py
对话语音是 OpenAI 实时 API 支持的核心用例。对话语音 API 需要:- 用户语音的文本转录、函数调用和 LLM 上下文的操作对于许多用例也很重要。
OpenAI 的实时 API 通过定义一系列通过 WebSocket 连接发送和接收的事件来实现这些功能。该 API 包括 9 种客户端事件(从客户端发送到服务器的事件)和 28 种服务器事件(从服务器发送到客户端的事件)。以下是所有 37 个事件的 Pydantic 事件定义: https://github.com/pipecat-ai/pipecat/blob/main/src/pipecat/services/openai_realtime_beta/events.py这个事件结构有很多优点。Python 中包括所有导入和 asyncio 样板的最小命令行客户端大约只有 75 行代码。
https://github.com/pipecat-ai/pipecat/blob/main/src/pipecat/services/openai_realtime_beta/events.py这个事件结构有很多优点。Python 中包括所有导入和 asyncio 样板的最小命令行客户端大约只有 75 行代码。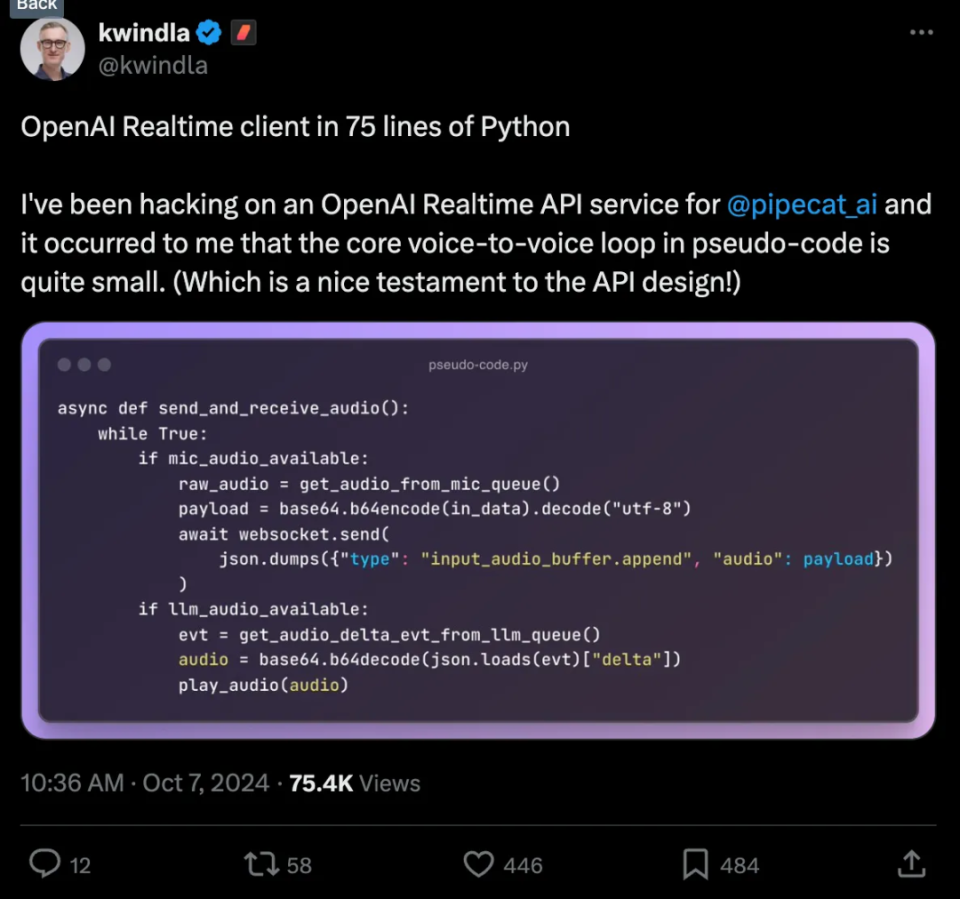 https://x.com/kwindla/status/1843118281911308355音频以 base64 编码块的形式发送和接收,嵌入在 input_audio_buffer.append 和 audio.delta 事件中。API 当前支持未压缩的 16 位、24khz 音频和压缩的 G.711 音频。
https://x.com/kwindla/status/1843118281911308355音频以 base64 编码块的形式发送和接收,嵌入在 input_audio_buffer.append 和 audio.delta 事件中。API 当前支持未压缩的 16 位、24khz 音频和压缩的 G.711 音频。- G.711 仅用于电话用例;与其他更现代的编解码器选项相比,音频质量相对较差。
- 未压缩的 16 位、24khz 音频的比特率为 384 千比特 / 秒。base64 编码开销将标称比特率推高至约 500 kbs。但 permessage-deflate 标准压缩将使比特率降至 300-400 kbs。
- 如果你关心的是实现实时延迟,那么 300kbs 的媒体流比人们通常希望通过 WebSocket 连接发送的媒体流要大。我们在后文也会谈谈延迟和 WebSockets。
人类希望在正常对话中得到快速响应,对话的响应时间为 500 毫秒是正常的,AI 长时间的停顿会让人感觉不自然。所以如果你正在构建对话式 AI 应用程序,语音到语音的延迟大概是 800 毫秒。尽管当今的 LLM 很难始终如一地实现这一点。OpenAI Realtime API 提供了非常好的推理延迟效果。对于位于美国的客户,API 的第一个字节时间约为 500 毫秒。如果我们的目标是总语音到语音延迟为 800 毫秒,那么音频处理和短语端点大约需要 300 毫秒。在理想条件下,这几乎是一项不可能完成的任务。测量语音到语音延迟的过程十分简单。你只需录制对话,将录音导入音频编辑软件,观察音频波形,并测量从用户语音结束到 LLM 语音输出开始之间的时间。如果你正在开发打算实际投产的对话式语音应用,定期监控延迟数据是非常重要的。在这些测试中加入模拟网络数据包丢失和抖动的功能,将会加分。以编程方式测量真正的语音到语音延迟具有挑战性,因为部分延迟发生在操作系统内部深处。因此,大多数可观察性工具仅测量推理到第一个字节的时间。这是总语音到语音延迟的合理代理,但请注意,此测量不包括短语端点时间(请参阅下一节)。许多「小」事情可能会引发延迟的「蝴蝶效应」。例如,蓝牙音频设备可能会增加几百毫秒的延迟。有关导致在 Web 浏览器中运行的语音到语音应用程序中延迟的所有因素的更多详细信息,请参阅此推文、博客以及 AI.Engineer 的演讲:- 推文链接:https://x.com/kwindla/status/1806129490411900940
- 博客链接:https://www.daily.co/blog/the-worlds-fastest-voice-bot/
在对话中,人们会轮流说话。在语音 AI 应用中,对话双方丝滑地切换回合需要做到两部分:- 应用判断人类是否已经说完,开始期待系统的响应。这被称为短语终点检测或回合检测(turn detection)。大多数应用都会尝试自动检测一个回合结束了,但有些应用会在界面上设置按钮,用户按住按钮才能说话,松开按钮表示说话结束。
- 如果用户在 LLM 说话时打断了它,一般来说,系统应该立即停止播放 LLM 的语音输出。然而,对于一些应用场景,这种行为需要是可配置的:有时候,即使用户打断了 LLM,也希望 LLM 能把话说完。
OpenAI 实时 API 内置了自动句尾检测和处理打断的功能。这些功能由 VAD(Voice Activity Detection)实现。自动轮次检测默认是开启的,但可以随时关闭。以下是 OpenAI 关于自动轮次检测的文档链接: https://platform.openai.com/docs/guides/realtime/realtime-api-beta#input-audio-buffer有多种 VAD 参数可配置,其中最重要的是 silence_duration_ms,即用户停止说话后,VAD 等待的时间长度(以毫秒为单位)。在这段时间后,会触发 input_audio_buffer.speech_stopped 事件并开始推理。OpenAI 在服务器端维护了一个音频缓冲区,应用程序可以通过发送 input_audio_buffer.append 事件持续地添加音频帧。在自动轮次检测模式下,应用程序只需持续发送音频数据,依靠 OpenAI 服务器端的 VAD 来识别用户何时开始和停止说话。当用户停止说话时,会触发多个 API 事件,LLM 随即开始生成响应。若用户再次开始说话,任何正在进行的响应将被中断,音频输出也会被清除。这种方法非常简单高效(无需编写任何客户端代码),并且效果显著。然而,在以下三种情况下,应用可能会选择关闭 OpenAI 的自动轮次检测功能:
https://platform.openai.com/docs/guides/realtime/realtime-api-beta#input-audio-buffer有多种 VAD 参数可配置,其中最重要的是 silence_duration_ms,即用户停止说话后,VAD 等待的时间长度(以毫秒为单位)。在这段时间后,会触发 input_audio_buffer.speech_stopped 事件并开始推理。OpenAI 在服务器端维护了一个音频缓冲区,应用程序可以通过发送 input_audio_buffer.append 事件持续地添加音频帧。在自动轮次检测模式下,应用程序只需持续发送音频数据,依靠 OpenAI 服务器端的 VAD 来识别用户何时开始和停止说话。当用户停止说话时,会触发多个 API 事件,LLM 随即开始生成响应。若用户再次开始说话,任何正在进行的响应将被中断,音频输出也会被清除。这种方法非常简单高效(无需编写任何客户端代码),并且效果显著。然而,在以下三种情况下,应用可能会选择关闭 OpenAI 的自动轮次检测功能:
禁用 OpenAI 的自动轮次检测功能后,客户端需在用户语音回合结束时发送两个 Realtime API 事件:input_audio_buffer.commit 和 response.create。以下是在用户开始说话时,如何调用这两个事件的 Pipecat 代码示例: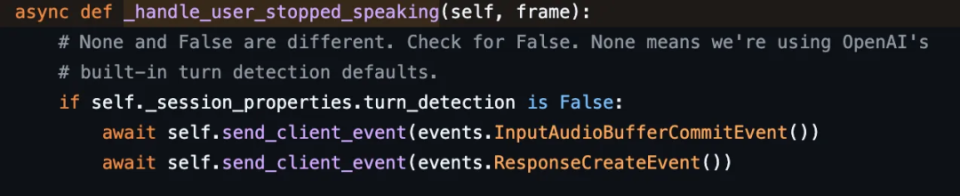 https://github.com/pipecat-ai/pipecat/blob/main/src/pipecat/services/openai_realtime_beta/openai.py#L145OpenAI VAD 似乎比 Pipecat 中的默认短语端点实现对背景噪音更敏感。Pipecat 使用输入音频能量的平滑运行平均值来相对于背景噪音自动调平。它还会忽略音频中的短尖峰,即使它们具有相当高的语音置信度,并支持高级音频处理。OpenAI 的 silence_duration_ms 参数默认为 500ms,Pipecat 将这个参数称为 stop_secs。这是一个很好的折衷方案,介于 LLM 响应时间过长和 LLM 响应过快之间。对于某些用例,最好选择较长的静音持续时间。例如,在工作面试环境中,让人们在谈话时有更多时间思考他们的答案通常会提供更好的体验。在这种情况下,800ms 甚至 1s 都是理想的。使用标准 VAD 时,除了语音 AI 演示之外,我们通常不建议将设置设置为低于 500 毫秒!有一些技术可以通过使用上下文感知短语端点来补充标准 VAD,或进行推测(贪婪)推理,或两者兼而有之,从而获得更快的响应时间。这些技术超出了本文的范围,但如果您对它们感兴趣,Pipecat Discord 是一个闲逛的好地方。
https://github.com/pipecat-ai/pipecat/blob/main/src/pipecat/services/openai_realtime_beta/openai.py#L145OpenAI VAD 似乎比 Pipecat 中的默认短语端点实现对背景噪音更敏感。Pipecat 使用输入音频能量的平滑运行平均值来相对于背景噪音自动调平。它还会忽略音频中的短尖峰,即使它们具有相当高的语音置信度,并支持高级音频处理。OpenAI 的 silence_duration_ms 参数默认为 500ms,Pipecat 将这个参数称为 stop_secs。这是一个很好的折衷方案,介于 LLM 响应时间过长和 LLM 响应过快之间。对于某些用例,最好选择较长的静音持续时间。例如,在工作面试环境中,让人们在谈话时有更多时间思考他们的答案通常会提供更好的体验。在这种情况下,800ms 甚至 1s 都是理想的。使用标准 VAD 时,除了语音 AI 演示之外,我们通常不建议将设置设置为低于 500 毫秒!有一些技术可以通过使用上下文感知短语端点来补充标准 VAD,或进行推测(贪婪)推理,或两者兼而有之,从而获得更快的响应时间。这些技术超出了本文的范围,但如果您对它们感兴趣,Pipecat Discord 是一个闲逛的好地方。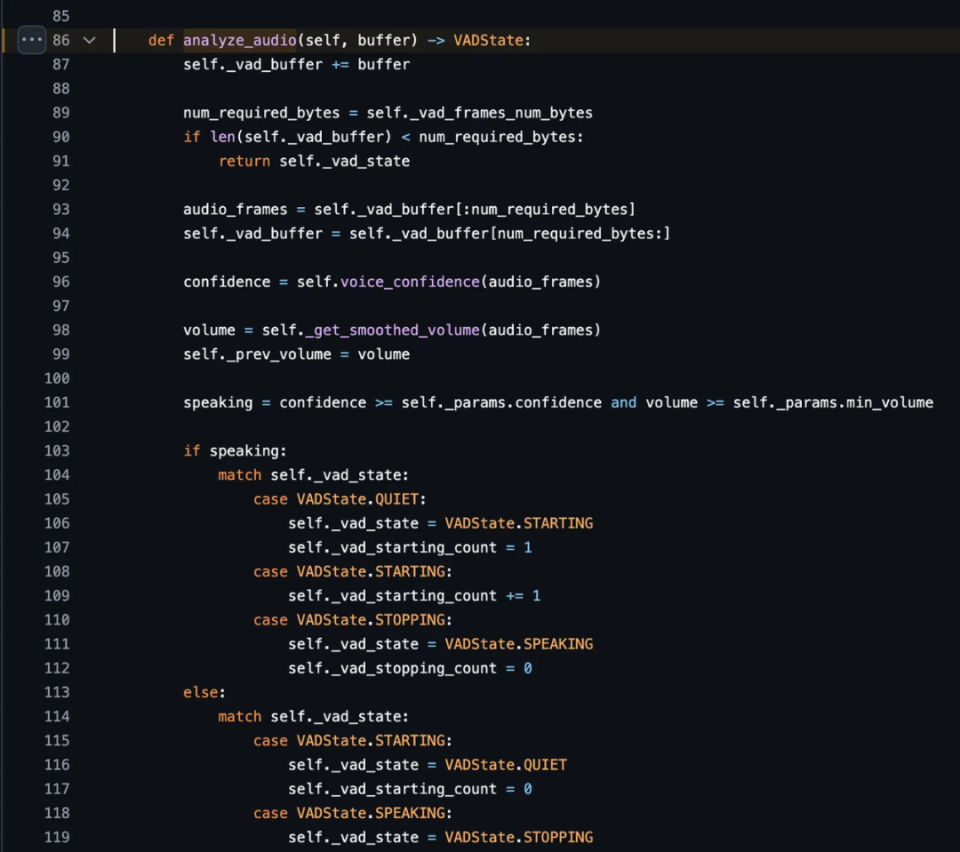 https://github.com/pipecat-ai/pipecat/blob/1d4be0139aeff2ee8cc214c81ae00e5948e35977/src/pipecat/audio/vad/vad_analyzer.py#L86LLM 本身是无状态的,因此每次有用户输入时,都需要将所有相关对话历史记录发送到 LLM。如果你之前构建过对话式 LLM 应用程序(文本或语音),你会熟悉跟踪对话历史记录并使用该历史记录创建不断增加的「上下文」。OpenAI Realtime API 为你进行对话管理,有两个巨大的好处:更简单的代码和更低的延迟。代码更简单,因为你不必跟踪应用程序中的对话历史记录。延迟较低有几个原因。每次你希望 LLM 生成响应时,不必重新发送大型上下文。这节省了一些网络开销。此外,当前的音频输入可以流式传输到 OpenAI 服务器,以便在请求推理时立即使用。最后,OpenAI 可以实现上下文缓存等内部优化。这一切带来一次巨大的胜利!有两个限制需要注意:最大上下文长度为 128000 tokens,单个对话的最大时间为 15 分钟。在音频对话中,你不太可能遇到 token 限制。音频每分钟使用大约 800 tokens。然而,15 分钟时长对于某些应用程序可能是一个限制。目前无法通过 OpenAI Realtime API 检索对话上下文、将「助手」音频消息加载到上下文中或可靠地加载多消息历史记录。参阅此存储库以获取测试用例:https://github.com/kwindla/openai-realtime-test-cases不过,实现持久对话和长时间对话是可能的。你需要将对话历史记录保存为文本。然后,在重新启动对话时,发送完整的对话历史记录(和适当的提示)作为新对话中的第一条消息。以下是 Pipecat 代码,它使用 OpenAI HTTP API 支持的相同消息列表格式来初始化对话:
https://github.com/pipecat-ai/pipecat/blob/1d4be0139aeff2ee8cc214c81ae00e5948e35977/src/pipecat/audio/vad/vad_analyzer.py#L86LLM 本身是无状态的,因此每次有用户输入时,都需要将所有相关对话历史记录发送到 LLM。如果你之前构建过对话式 LLM 应用程序(文本或语音),你会熟悉跟踪对话历史记录并使用该历史记录创建不断增加的「上下文」。OpenAI Realtime API 为你进行对话管理,有两个巨大的好处:更简单的代码和更低的延迟。代码更简单,因为你不必跟踪应用程序中的对话历史记录。延迟较低有几个原因。每次你希望 LLM 生成响应时,不必重新发送大型上下文。这节省了一些网络开销。此外,当前的音频输入可以流式传输到 OpenAI 服务器,以便在请求推理时立即使用。最后,OpenAI 可以实现上下文缓存等内部优化。这一切带来一次巨大的胜利!有两个限制需要注意:最大上下文长度为 128000 tokens,单个对话的最大时间为 15 分钟。在音频对话中,你不太可能遇到 token 限制。音频每分钟使用大约 800 tokens。然而,15 分钟时长对于某些应用程序可能是一个限制。目前无法通过 OpenAI Realtime API 检索对话上下文、将「助手」音频消息加载到上下文中或可靠地加载多消息历史记录。参阅此存储库以获取测试用例:https://github.com/kwindla/openai-realtime-test-cases不过,实现持久对话和长时间对话是可能的。你需要将对话历史记录保存为文本。然后,在重新启动对话时,发送完整的对话历史记录(和适当的提示)作为新对话中的第一条消息。以下是 Pipecat 代码,它使用 OpenAI HTTP API 支持的相同消息列表格式来初始化对话: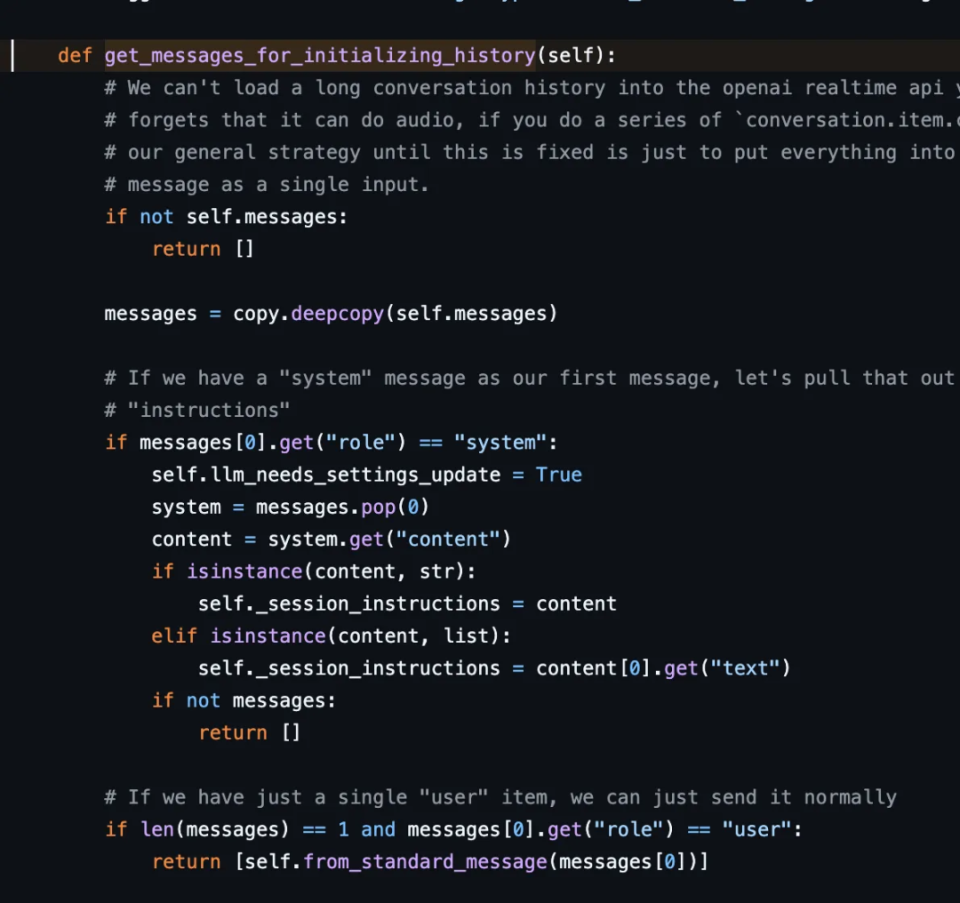 https://github.com/pipecat-ai/pipecat/blob/main/src/pipecat/services/openai_realtime_beta/context.py#L76LLM 的音频生成速度比语音输出速度更快。OpenAI 将服务器端 LLM 响应添加到对话上下文中,速度与生成的速度一样快。但讲话的播放速度较慢。如果用户中断 LLM,则用户将只能听到 LLM 响应的一部分。在大多数情况下,您希望对话历史记录仅包含用户实际听到的 LLM 响应部分。您需要发送对话.item.truncate 事件以强制服务器端上下文匹配用户听到的音频范围。请注意,无论您是否使用自动转弯检测 (server_vad),您都需要执行此操作。以下是 Pipecat 代码,用于计算用户听到的音频的持续时间并调用对话.item.truncate:
https://github.com/pipecat-ai/pipecat/blob/main/src/pipecat/services/openai_realtime_beta/context.py#L76LLM 的音频生成速度比语音输出速度更快。OpenAI 将服务器端 LLM 响应添加到对话上下文中,速度与生成的速度一样快。但讲话的播放速度较慢。如果用户中断 LLM,则用户将只能听到 LLM 响应的一部分。在大多数情况下,您希望对话历史记录仅包含用户实际听到的 LLM 响应部分。您需要发送对话.item.truncate 事件以强制服务器端上下文匹配用户听到的音频范围。请注意,无论您是否使用自动转弯检测 (server_vad),您都需要执行此操作。以下是 Pipecat 代码,用于计算用户听到的音频的持续时间并调用对话.item.truncate: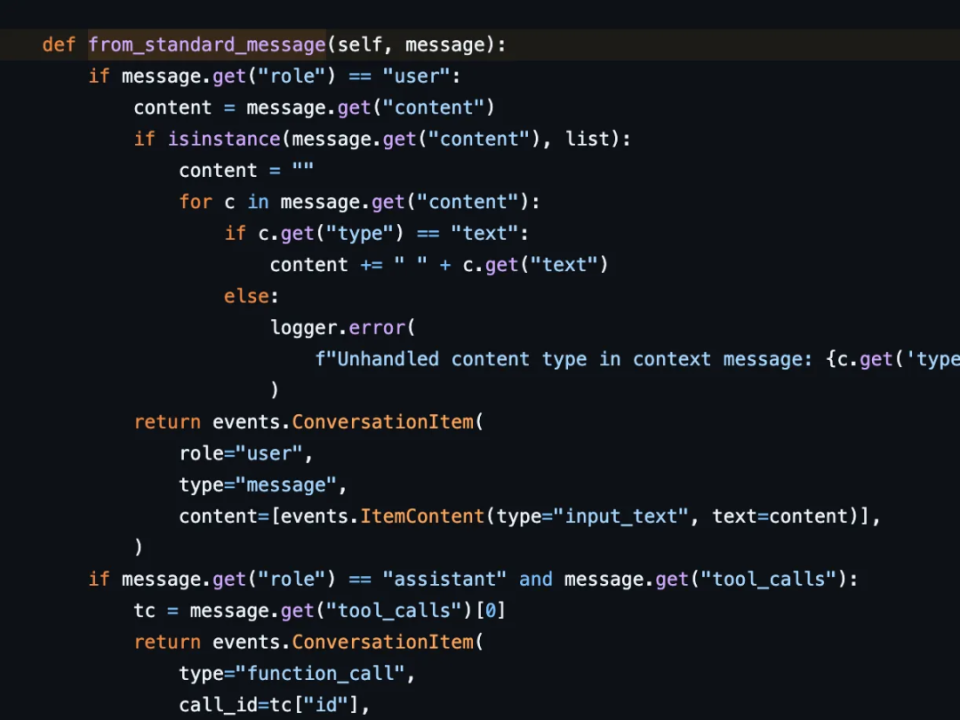 https://github.com/pipecat-ai/pipecat/blob/main/src/pipecat/services/openai_realtime_beta/context.py#L49对于许多用例来说,用户输入和 LLM 输出的转录都很重要。保存对话以便用户稍后可以返回就是一个例子。许多企业用例需要对话记录来满足内容审核、后处理需求或合规性原因。OpenAI Realtime API 始终提供 LLM 输出的转录。输入转录默认关闭,但可以通过在配置会话时设置 input_audio_transcription 字段来启用。输出转录由 LLM 本地生成,与音频输出紧密匹配。输入转录由单独的模型生成,并不总是与模型 “听到” 的内容匹配。对于某些用例来说,这可能是一个问题。如果转录数据包含语言字段,这也会很有用。(许多语音人工智能用例都是多语言的。)目前还没有办法将输出转录与语音定时对齐。这使得当用户中断时很难截断文本输出,并且很难构建诸如单词精确的流文本字幕之类的东西。输入音频转录也可能落后于模型输出几秒钟。如果您需要使用转录进行内容审核,您可能需要使用您自己的转录模型和门短语终结于转录完成或内容审核检查本身之后。最后,请注意 Realtime API 消息的内容格式与 OpenAI HTTP API 的格式不同。以下是从 HTTP API 格式转换为 Realtime API 格式的 Pipecat 代码:函数调用在 OpenAI Realtime API 中运行得非常好(所有 GPT-4 系列模型都是如此)。
https://github.com/pipecat-ai/pipecat/blob/main/src/pipecat/services/openai_realtime_beta/context.py#L49对于许多用例来说,用户输入和 LLM 输出的转录都很重要。保存对话以便用户稍后可以返回就是一个例子。许多企业用例需要对话记录来满足内容审核、后处理需求或合规性原因。OpenAI Realtime API 始终提供 LLM 输出的转录。输入转录默认关闭,但可以通过在配置会话时设置 input_audio_transcription 字段来启用。输出转录由 LLM 本地生成,与音频输出紧密匹配。输入转录由单独的模型生成,并不总是与模型 “听到” 的内容匹配。对于某些用例来说,这可能是一个问题。如果转录数据包含语言字段,这也会很有用。(许多语音人工智能用例都是多语言的。)目前还没有办法将输出转录与语音定时对齐。这使得当用户中断时很难截断文本输出,并且很难构建诸如单词精确的流文本字幕之类的东西。输入音频转录也可能落后于模型输出几秒钟。如果您需要使用转录进行内容审核,您可能需要使用您自己的转录模型和门短语终结于转录完成或内容审核检查本身之后。最后,请注意 Realtime API 消息的内容格式与 OpenAI HTTP API 的格式不同。以下是从 HTTP API 格式转换为 Realtime API 格式的 Pipecat 代码:函数调用在 OpenAI Realtime API 中运行得非常好(所有 GPT-4 系列模型都是如此)。- 与对话消息的格式一样,工具格式与 OpenAI HTTP API 略有不同。
tools = [ { "type": "function", "function": { "name": "get_current_weather", "description": "Get the current weather in a given location", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city and state, e.g. San Francisco, CA", }, }, "required": ["location"], } } }]
tools = [ { "type": "function", "name": "get_current_weather", "description": "Get the current weather", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city and state, e.g. San Francisco, CA", }, "format": { "type": "string", "enum": ["celsius", "fahrenheit"], "description": "The temperature unit to use. Infer this from the users location.", }, }, "required": ["location", "format"], }, }]
- 通过流事件 response.function_call_arguments.delta 和 function_call_arguments.done
如果您从 HTTP API 进行移植并希望保留尽可能多的现有代码结构,则流事件可能会很有用。但令人高兴的是,Realtime API 使得从 response.done 事件中提取函数调用结构变得非常简单。流对于函数调用来说并不是很有用 —— 在调用函数之前,您需要完整的函数调用结构 —— 并且在使用 HTTP API 时,从流式响应块中组装函数调用数据一直是一个小麻烦。下面是从 response.done 事件的输出字段中提取函数调用信息的 Pipecat 代码:https://github.com/pipecat-ai/pipecat/blob/main/src/pipecat/services/openai_realtime_beta/openai.py#L469对话式 AI 的使用场景,成本通常会随着会话长度呈指数增长。大多数对话式 AI 应用和 API 都会在每次推理请求中使用完整的会话历史,OpenAI 实时 API 也不例外。不过,OpenAI 实时 API 能够自动缓存并重复利用已发送的输入 tokens。缓存的音频 tokens 成本比非缓存的低 80%,在长对话中这可以大幅降低成本。 - 1 minute — $0.11 - 2 minutes - $0.26 - 5 minutes - $0.92 - 10 minutes - $2.68 - 15 minutes - $5.28
OpenAI 不会为接近静音的音频输入生成 tokens。成本估算基于假设对话中 70% 的时间是用户实际说话的时间。如果实际说话时间比例更低,成本会相应降低。预计 OpenAI 会持续降低实时 API 的成本。但如果你的预算紧张,可以考虑每隔几轮对话重置上下文,用文本替换音频消息,也可以使用摘要功能进一步减少输入 tokens 的数量。以下是一个成本计算器表格,你可以调整其中的参数算一算输入 token 的成本:https://docs.google.com/spreadsheets/d/1EL-mjqlmj4ehug8BjmgmAFm9uFZtZXY9N9EvqLm8Ebc/edit?usp=sharingOpenAI 实时 API 使用 WebSockets 进行网络传输。WebSockets 非常适合用于服务器之间的通信,尤其是在对延迟要求不高的场景中,以及在原型开发和一般性开发测试中。如果你正在开发一个基于 OpenAI 实时 API 的浏览器或原生移动应用,并且对会话延迟有严格要求,建议使用 WebRTC 连接。具体来说,用 WebRTC 将音频从你的应用发送到服务器,接收音频,然后在服务器端直接调用 OpenAI 实时 API。Pipecat 支持 WebRTC、WebSockets 和 HTTP 传输,可以轻松构建「客户端」——「服务器」—— [推理服务器] 的架构。但对于生产环境中的客户端 —— 服务器实时媒体连接,不推荐使用 WebSockets。理由如下:WebSockets 基于 TCP 协议,因此音频流会遇到「首阻塞问题」。如果某个数据包延迟,后续的数据包也会被阻塞。此外,TCP 协议会尝试重新发送丢失的数据包,但在实时场景中,如果这些数据包到达时已经过期,就毫无意义,还可能进一步增加延迟。用 WebRTC 就可以解决这些问题。首先,WebRTC 使用的 Opus 音频编解码器与 WebRTC 的带宽估算和数据包调度(拥塞控制)逻辑紧密结合。这使得 WebRTC 音频流能够很好地适应各种现实网络环境。Opus 音频编解码器具有非常优秀的前向纠错能力,能有效处理音频流中的丢包问题,保持音频稳定,(不过,这需要网络能及时丢弃延迟的数据包且没有首阻塞问题才行)。WebRTC 发送和接收的音频会自动添加时间戳,因此播放和中断逻辑的实现都变得非常简单。而在 WebSockets 中,处理起来则要困难得多。此外, WebRTC 自带出色的回声消除、噪声消减和自动增益控制功能。如果使用 WebSockets,则需要自己想办法将这些音频处理功能集成到应用中。最后,在长距离网络传输中,延迟和不稳定性是不可避免的。为了减少这些问题,可以通过「靠近用户的中转节点」(路由器)优化连接,从而提升实时媒体的性能,而 WebRTC 平台会自动帮你完成这部分优化。- 如果你对媒体传输网络协议的设计感兴趣,可以参考这篇关于 RTMP、HLS 和 WebRTC 的技术概览:https://www.daily.co/blog/video-live-streaming/
- 如果想深入了解 WebRTC 的路由机制,可以参考 Daily 详解其全球 WebRTC 基础设施的文章:
几乎所有支持对话的语音应用都需要处理音频的功能,特别是回声消除。Media Capture and Streams API 为 Chrome、Safari 和 Edge 浏览器提供了相对成熟可靠的回声消除功能,开发者可以放心使用。我们强烈建议不要将 Firefox 作为开发和测试的浏览器。Firefox 的回声消除和音频流管理功能较差且不稳定。你可能得花费大量时间修复 Firefox 的特有 bug,而这些问题在其他浏览器中完全不存在。因此,建议优先针对 Chrome 和 Safari 开发功能,后续再考虑是否要适配 Firefox。浏览器的 WebRTC 和原生 SDK 通常会默认开启高质量的回声消除、消减底噪和自动增益控制功能。需要注意的是,回声消除必须在客户端设备上完成,而其他类型的音频处理可以在服务器端实现。例如,Pipecat 集成了 Krisp 的降噪和分离说话人模型,可以在服务器端处理音频。每个 API 都是工程的产物,要权衡软件设计和开发中的各种限制。优秀的 API 力求需求明确,找到功能细分的「黄金点」,可以让简单的事情更简单,也能让复杂的事情成为可能。把 OpenAI 实时 API 集成到 Pipecat 中是一件很有趣的事情。这两种支持对话式语音 AI 的方法有很多相同之处。OpenAI 的事件(event)可以直接映射成 Pipecat 的帧类型。OpenAI 实时 API 解决的问题类型或关注的领域,与 Pipecat 用户已经习惯的问题非常相似,对 OpenAI 的设计会很熟悉,不需要花太多时间去适应。但它们在设计的底层架构上有很大的差异,这种差异可能是因为两者的定位和使用场景不同。OpenAI 实时 API 的事件架构可以轻松集成到任何编程语言或框架中。发送事件时,只需传输一些 JSON(或类似格式)数据;接收事件时,通过读取循环将数据分发到相应函数即可。相比之下,Pipecat 是一种数据流架构,受多年来多媒体数据处理框架(如 GStreamer)的影响较大,在设计上强调模块化和流水线化。在 OpenAI 实时 API 中,核心构建块是「事件(event)」;在 Pipecat 中,核心构建块是「帧处理器(frame processor)」。一个 Pipecat 中的语音到语音循环可能看起来是这样的:pipeline = Pipeline( [ transport.input(), context_aggregator.user(), openai_realtime_llm, context_aggregator.assistant(), transport.output() ])
在此基础上添加语音转文本和文本转语音的处理器,这种架构可以兼容任何大型语言模型(LLM)。pipeline = Pipeline( [ transport.input(), context_aggregator.user(), stt, llm, tts, context_aggregator.assistant(), transport.output() ])
以下是一个更复杂的 Pipecat 流程,整合了多种功能模块,能够高效地处理客户端命令和事件。通过 Webhook 实现函数调用, 内置了处理计费、监控流程,错误管理功能。
pipeline = Pipeline( [ el, transport.input(), rtvi, user_aggregator, openai_realtime_llm, rtvi_speaking, rtvi_user_transcription, rtvi_bot_llm, rtvi_bot_transcription, webhooks_processor, ml, rtvi_metrics, transport.output(), rtvi_bot_tts, assistant_aggregator, ])
实时语音 API 需要判断你的话在哪里结束,好接上对话。以下一个是减少延迟的实验性方案。其中,语音活动检测(VAD)负责听声音有没有停下来,LLM 来判断刚才说的是不是完整的一句话,是不是有话没说完。这两个判断将放在并行的子流程中同时运行。pipeline = Pipeline( [ transport.input(), stt, context_aggregator.user(), ParallelPipeline( [ # Pass everything except UserStoppedSpeaking to the elements after # this ParallelPipeline FunctionFilter(filter=block_user_stopped_speaking), ], [ # Ignore everything except an OpenAILLMContextFrame. Pass a specially constructed # LLMMessagesFrame to the statement classifier LLM. The only frame this # sub-pipeline will output is a UserStoppedSpeakingFrame. statement_judge_context_filter, statement_llm, completeness_check, ], [ # Block everything except OpenAILLMContextFrame and LLMMessagesFrame FunctionFilter(filter=pass_only_llm_trigger_frames), llm, bot_output_gate, # Buffer all llm output until notified. ], ), tts, user_idle, transport.output(), context_aggregator.assistant(), ])
更多资源
Pipecat 代码,可以通过 Pipecat 来调用 OpenAI 的实时功能,尤其是其中的 Pydantic 模版可能对其他项目特别有用: