来源:中国图象图形学报、一点人工一点智能 | 首图图源:网络
作者:胡学敏,黄婷玉,余雅澜等
全文 1.5W+ 字,预计阅读 45-50 分钟
自动驾驶汽车作为未来交通的重要发展方向,决策技术是其进行安全高效行驶的关键。基于成本和安全性的考虑,最新的自动驾驶决策技术往往先在仿真环境中研究,再在现实世界中应用,故在自动驾驶决策领域,仿真到现实的方法能帮助自动驾驶系统更有效地进行学习、训练和验证。然而,仿真环境和现实环境之间的差距会在这些模型和技术转移到真实车辆时带来挑战,这种仿真到现实环境域差距的问题促使研究人员探索解决该问题的途径,并且提出各种有效的方法。本文将这些方法总结为两大类:虚实迁移和平行智能。前者通过不同方法将在模拟环境中训练的车辆决策迁移到现实环境中,以解决域差距问题;后者通过构建虚拟的人工系统和现实的物理系统,将二者进行交互、比较、学习和实验,从而解决自动驾驶决策在现实环境中的适配问题。本文首先从虚实迁移和平行智能的原理,以及自动驾驶决策领域应用的角度进行了详细综述,这也是首次从平行智能的角度来思考自动驾驶决策技术中仿真到现实环境的问题,然后总结了搭建仿真环境常用的自动驾驶模拟器,最后归纳了仿真到现实环境的自动驾驶面临的挑战和未来的发展趋势,既为自动驾驶在现实场景的应用与推广提供技术方案,也为自动驾驶研究人员提供新的想法和方向。 作为人工智能领域的重要技术之一,自动驾驶技术能够有效提高交通效率和出行的安全性(Hu等,2018)。决策规划模块是自动驾驶系统的一个重要组成部分,它桥接了感知模块和控制模块。其目的是利用车辆感知的环境信息,同时结合车辆自身的位置和速度等状态,以及交通规则等因素,生成有效的行为决策,让自动驾驶汽车安全、平稳地到达目的地。 传统自动驾驶决策技术的研究往往依赖于现实世界的数据和场景,但是完全在现实世界中训练车辆智能体需要采集大量来自现实世界的数据,或者需要与现实环境进行不断地交互与试错。这样会导致训练成本非常高,且有些边界场景的数据无法获取。因此,目前大多数的自动驾驶决策方法通常会先在高保真的模拟器中进行训练和测试,然后再部署到现实环境中。然而,仿真环境和现实环境之间总是会存在一定的差异,称之为域差距(Tobin等,2017),这种差距往往是由模型不匹配、有限的探索或者分布偏移导致的。其中,模型不匹配是指仿真训练环境可能没有捕捉到现实环境的所有复杂性和细节;有限的探索是指车辆在仿真环境中训练时没有充分探索到全部的现实动作,无法很好地概括现实世界中未见过的情况;分布偏移是指仿真和现实环境中的行为分布上的不同。因此,如何减小仿真与现实环境之间的域差距,让仿真环境中训练的自动驾驶决策能够更好地应用到现实环境,是当前自动驾驶领域亟待解决的问题。 目前很多工作都在研究仿真到现实的方法,并且在很多任务中取得了成功,如目标检测(Zhong等,2022)、导航任务(Truong等,2021)、飞行器控制(Xiao等,2023;Allamaa等,2022)和机器人控制(Byravan等,2022)等。自动驾驶作为人工智能的重要领域,仿真到现实也在该领域取得了重要的突破,然而大量仿真到现实的决策技术综述主要是从虚实迁移的角度来总结的(Zhao等,2020;Salvato等,2021),且没有专注于自动驾驶决策技术(Miao等,2023)。本文在考虑虚实迁移的基础上,融入了平行智能技术,将仿真到现实的决策技术分为两大类:虚实迁移和平行智能。这也是首次从平行智能的角度来思考自动驾驶决策技术中的仿真到现实问题。 虚实迁移的主要思想是将从仿真环境中学到的策略迁移到现实世界,从而减少域差距。虚实迁移方法可以将学习与仿真相结合,对复杂的现实环境进行初步建模后不断学习,通过逐步迭代使得模型能够逐渐适应于更为复杂和多变的场景,并能将仿真中得到的模型直接应用于现实世界。在现实与仿真环境的对比中,仿真环境可以给车辆智能体非常明确的信息,但是现实世界中,这一信息会受到真实传感器捕捉能力和一些复杂环境的影响,例如温度、湿度等。为了解决这些因素造成的域差距,本文将虚实迁移分为6类方法来介绍如何解决这一问题,包括迁移学习、课程学习、知识蒸馏、元学习、鲁棒强化学习和其他虚实迁移方法。如图1的A部分所示,虚实迁移方法的总体思想是通过其衍生的6类方法将知识与经验从人工系统中迁移到现实世界里。这6种方法共同的关键是通过训练一个可迁移的神经网络,将在仿真环境学到的决策行为和控制车辆动作的模型迁移到现实场景中,以此减少域差距。 平行智能技术由Wang等人(2016a)提出,它是基于ACP(人工社会(artificial societies)、计算实验(computational experiments)、平行执行(parallelexecution))的一种深度融合仿真与现实场景的新方法。其主要思想如图1方法中双向箭头所示,平行智能通过人工系统和物理系统进行反复交互形成一个完整的系统,利用计算实验对特定场景进行试错和优化,并通过平行执行实现决策寻优,从而达到减少域差距的目的。其中,计算实验分为描述学习、预测学习和指示学习,由这3个步骤将模型逐渐从仿真环境过渡到现实世界。该方法将信息、仿真和决策融为一体,通过计算、试验和评估的方式,为研究复杂系统的控制与管理提供了新思路。近年来,平行智能技术成为人工智能领域中的新兴热点,并在自动驾驶决策技术领域取得了显著的研究成果和实践效益(Chen等,2022)。平行智能技术与虚实迁移技术都将物理的空间扩展到虚拟的空间,通过虚实交互对现实世界建模,智能体通过仿真环境与现实环境学习知识与经验。相比于虚实迁移的方法,平行智能作为一种更先进、层次更高以及应用范围更广的技术,能够使仿真环境和现实环境之间相互作用,以形成闭环的人工智能系统,从而更有效地解决域差距的问题。 图1概述了本文的工作。首先分析了仿真到现实方法的研究背景,然后将其分为虚实迁移和平行智能两种主要的方法,并分别对这些方法进行分类总结;随后,对模拟器进行了简要回顾;最后,本文总结了该方向的关键问题以及未来趋势。1)分析和总结了虚实迁移和平行智能的现有方法,以及解决仿真到现实域差距问题的原理,这也是首次从平行智能的角度探讨解决仿真到现实域差距的途径。2)归纳和讨论了虚实迁移和平行智能方法在自动驾驶决策规划领域的应用,为自动驾驶在现实场景的应用与推广提供技术方案。3)探讨了自动驾驶决策的应用和仿真到现实方法中存在的问题与挑战,并概括了未来发展趋势,为自动驾驶研究人员提供新的想法和方向。
在自动驾驶的发展历程中,仿真到现实的决策技术逐渐崭露头角,为提高自动驾驶系统的泛化性和安全性提供了创新性的解决方案。最初的自动驾驶决策技术主要依赖于实际道路测试,但受限于成本和风险问题,模型在真实环境中面对的场景较为有限。随着计算机性能的提升和虚拟仿真技术的成熟,研究者们开始将仿真引入到自动驾驶决策中,在虚拟环境中模拟车辆行驶的各种情况。然而,虚拟环境和真实环境总会存在域差距,导致在将虚拟环境中训练的车辆决策模型应用于现实世界中时效果有限。近年来,针对这种域差距的问题,研究者们开始关注仿真到现实环境的决策技术,以确保在虚拟环境中训练的模型能够有效应用于现实环境,并保持高效的决策能力。 本文将仿真到现实技术分为虚实迁移和平行智能技术。图2表示了仿真到现实关键成就的时间路线图,其中包括虚实迁移的6类方法的提出以及平行智能的发展历程。仿真到现实的历史可以追溯到1987年的元学习(Schmidhuber,1987),元学习器以少量的元学习数据为基础,通过不断学习各种任务学习经验,以更好地迁移到现实任务中。随后,系统识别(Ljung,1998)方法也逐渐用于仿真到现实。随着强化学习不断发展,鲁棒强化学习(Morimoto和Doya,2005)和课程学习(Bengio等,2009)与其相结合也为自动驾驶决策技术的发展提供了更好的虚实迁移泛化能力。针对决策模型过于复杂而难以部署的问题,Hinton等人(2015)提出了一个名为知识蒸馏的数据压缩方法用于仿真到现实的迁移。此外,为了提高模型对于决策变化的适应性,研究人员提出迁移学习(Weiss等,2016)和域随机化(Tobin等,2017)。 对平行智能的研究最早可以溯源至20世纪80年代,之后在ACP方法的基础上由王飞跃(2004a)正式提出。该理论不断发展并逐渐应用到交通、医疗、制造等领域。为了解决城市交通中存在的安全等关键问题,王飞跃提出平行应急(王飞跃,2007a)、平行交通(王飞跃,2007b)的方法,给自动驾驶决策技术奠定了基础。随后,平行智能的发展逐步扩展到军事领域,王飞跃研究出平行控制(王飞跃,2013)、平行情报(王飞跃,2015)等应用框架,通过利用ACP方法应对物理域、网络域和感知域的军事行动,这也为自动驾驶提供了决策技术支持。近年来,机器学习逐渐步入自动驾驶领域,李力等人(2017)在平行智能理论的基础上结合多种机器学习框架的优点提出平行学习这一概念,并应用于自动驾驶领域,提出了平行驾驶技术。与此同时,以平行智能为基础的平行感知(孟祥冰等,2017)、平行医疗(王飞跃等,2017b)、平行网络(王飞跃等,2017a)和平行制造(王飞跃等,2018a;Yang等,2022)这些概念相继出现,再次推动了平行智能的发展。在这些概念的影响下,研究人员将决策规划理念融入到平行智能中,为自动驾驶复杂系统的控制提供了平行规划(Chen等,2019)方法。除了发展理论技术,服务于其他领域的相关应用也得到了重视,如平行海洋监测系统(苏振东等,2018)、平行点云(田永林等,2020)、平行哲学(王飞跃,2021a)、平行光场(王飞跃等,2021)、平行管理(王飞跃,2022)、平行医学(王飞跃,2021b)和平行轮胎(张向文和王飞跃,2022)等。
为了解决域差距问题,研究人员提出了虚实迁移的方法,即在虚拟的仿真环境中训练,并将学到的知识和决策通过一定的方法迁移到现实场景中。目前,虚实迁移的方法主要包括鲁棒强化学习、元学习、课程学习、知识蒸馏、迁移学习和其他仿真到现实方法,如系统识别和域随机化。表1为一些典型的虚实迁移模型。 表1 典型的基于虚实迁移的自动驾驶决策方法
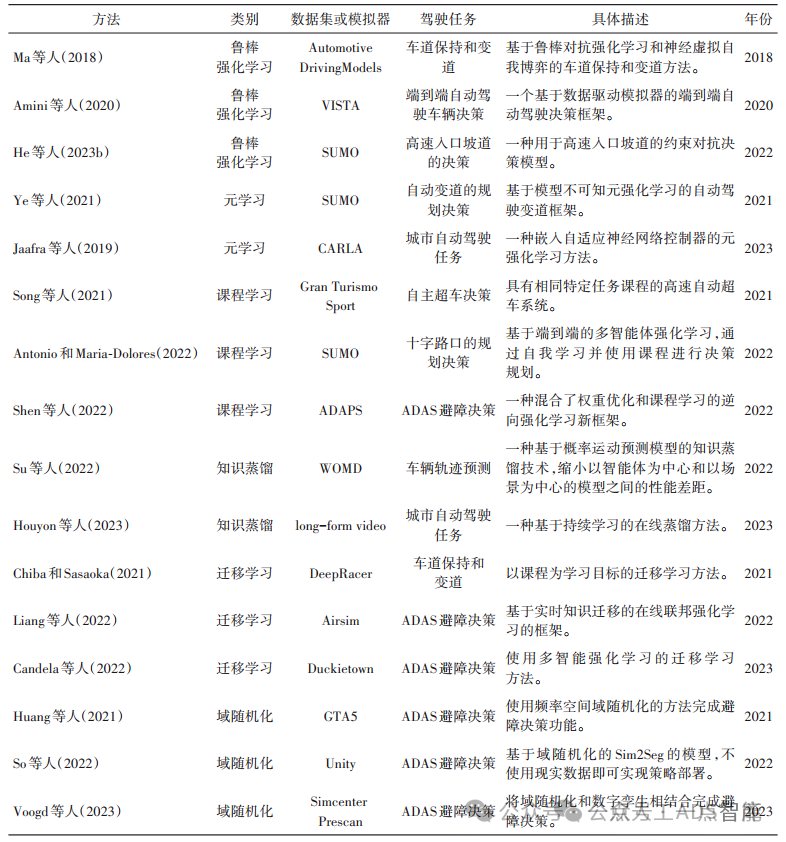
Morimoto和Doya(2005)最早提出了鲁棒强化学习的概念,这是一种基于H∞ 最优控制理论的新强化学习范式。该范式针对状态的不确定性,使用了迷你最大博弈论,同时明确地考虑了决策模型中的输入干扰和建模误差,使得其在仿真决策训练过程中更好地泛化到现实环境,进而缩短虚实环境之间的差距。 H∞最优控制理论与博弈论密切相关,鲁棒强化学习将迷你最大博弈论引入对抗强化学习框架,即鲁棒对抗强化学习(Pinto等,2017)。其主要思想是在仿真环境中训练对手的决策行为并产生扰动或挑战,模仿现实环境中的分布变化和差异,减少虚实场景之间分布偏移带来的域差距,以此提高鲁棒性(隋晨红等,2023)。Ma等人(2018)和He等人(2023b)使用相同的思想,将鲁棒对抗强化学习扩展到决策应用中,模型会生成对抗性环境中的干扰,有效地防止系统扰动引起的部分域差距。He等人(2023a)还提出了一种面向自动驾驶的高速公路入口匝道决策的策略,将高速公路交叉口的环境建模为对抗环境来约束车辆的决策行为,并使用白盒对抗攻击技术来生成对抗性环境中的干扰,有效地防止系统扰动引起的部分域差距。 鲁棒对抗强化学习是将系统中的不确定性表达为干扰力,但是在大多数自动驾驶决策技术的研究中对该干扰力的描述没有涉及线性和非线性函数逼近的问题。为了对其进行进一步的研究,Tessler等人(2019)通过动作扰动引入鲁棒性,提出了两个新的鲁棒性标准:概率和噪声动作鲁棒性。基于动作扰动的鲁棒性通过扰动智能体和对手行动之间的线性组合,提高了鲁棒强化学习处理非线性问题的能力和智能体的决策迁移能力。此外,Amini等人(2020)提出了一个使用数据驱动的模拟器进行端到端自动驾驶车辆动作决策的框架,该框架能够学习模拟器中的道路,并生成一条与该道路外观和语义一致的新轨迹,同时能够将该决策迁移到其他道路中。图3的A部分表明了数据驱动模拟器合成一个新的轨迹空间并用于学习虚拟智能体的控制策略;图3的B部分表示该方法学习的鲁棒控制决策能够直接迁移到现实世界中,实现仿真到现实的决策迁移。 图3 基于数据驱动的端到端自动驾驶车辆决策模型(Amini等,2020)元学习(Schmidhuber,1987)在近些年来受到了极大的关注,它的概念是学会学习,其本质是模型能从广泛的任务中学习到先验经验,从而更快地学习新任务。通常地说,在为现实环境构建模型时,元学习能基于对应仿真环境的相关经验,更好地进行迁移。元学习已被证明在多种场景中具有优势,例如单任务学习(Zhou等,2020)、多任务学习(Song等,2022)、少样本场景(Baik等,2021;杜彦东等,2023;董杨洋等,2023)和神经架构搜索(Real 等,2019)等。 基于元学习的决策系统可以共享之前的知识,同时更好地处理复杂的任务。Stefik(1981)提出了一种称为元决策的控制结构,使智能体能够推理自己的决策过程。Gul等人(2021)基于元学习提出一种智能体路径决策算法,通过混合两种启发式算法实现图中路径点的生成。 鲁棒性强化学习的快速发展为元学习应用在自动驾驶决策提供了新的契机。研究人员将元学习与强化学习相结合,提出了一种与模型无关的元强化学习算法,称为模型不可知元强化学习(Finn等,2017)。该模型仅需少量数据即可实现快速收敛,解决了以往研究中只关注当下初始化参数的问题。为了快速有效地在线适应新任务,Ye等人(2021)提出了一种基于模型不可知元强化学习的自动驾驶变道决策方法,使得智能体能够在不同的交通环境下进行换道操作。如图4所示,该方法对任务场景和车辆模型的组合进行多任务分类,将得到的状态和奖励作为元学习的输入。元学习器将参数更新并作用于低级神经网络,低级神经网络将学习结果反馈于元学习,完成自动驾驶变道操作的决策任务。元学习器使车道变换的模型能够有效适应新场景,同时将仿真环境中的知识迁移到现实环境,以解决域差距的问题。此外,Jaafra等人(2019)提出了一种嵌入自适应神经网络控制器的元强化学习方法,目的是在不断变化的自动驾驶任务条件下进行有效的决策。其中,元学习方法能够让智能体从先前的任务中学到如何根据环境更新来确定策略的经验,从而增强泛化性,以解决在不同环境中的域差距。 图4 基于模型不可知元强化学习的自动驾驶变道方法(Ye等,2021)课程学习(Bengio等,2009)是一种训练策略,在该策略中,模型通过先学习简单的任务,然后再学习更复杂的任务来积累知识。其中,模型通过逐渐引入更真实的元素提高智能体对现实场景的适应性,以此提高迁移的效率。 最初的课程学习是仅仅由人类先验知识设计不使用其他算法,这样的设计不仅缺少了专家的经验,并且其课程也不能灵活变通,同时会导致迁移能力较差。于是Kumar等人(2010)提出了自步学习的概念。其中模型能动态地确定课程以适应学习者的学习速度,解决了课程学习中任务固定导致模型不具泛化性的问题。Wang等人(2023)在自步学习方法的基础上,引入了课程对抗学习。该模型包含3个从简单到复杂的课程,通过对抗学习的方法让模型学习到更能适应恶劣天气的驾驶决策,以此更好地迁移到现实世界。 为了解决自步学习方法在训练开始时存在不确定性的问题,研究人员提出了基于强化学习的课程学习模型(Graves等,2017)。该模型在每个训练周期中,基于强化学习的教师模型将根据学生模型的反馈动态地选择用于训练的任务。使用基于强化学习的课程学习方法被证明能够更有效地解决动态场景中的复杂驾驶决策任务(Florensa等,2017;Qiao等,2018)。为了提高自动驾驶决策迁移的适用性,Song等人(2021)提出了一种基于课程学习的高速自主超车决策系统,该系统在训练过程中使用具有相同特定任务的课程来训练车辆智能体。该框架在竞速、超车和避障3个方面上,分别使用了课程学习的方法,将从简单到困难的决策任务逐一解决。基于强化学习的课程学习能够解决无法利用仿真或现实驾驶场景产生的大量数据的问题,提高了仿真到现实决策方法的迁移效率。逆向强化学习的方法也给研究人员带来了新的思考,Shen等人(2022)提出一种混合了权重优化和课程学习的逆向强化学习框架,用基于上下文的感知多传感器,通过混合权重信赖域优化课程学习,从而得到更好的决策迁移能力。此外,强化课程学习在多智能体决策的应用也十分广泛(Yang等,2021;Antonio和Maria-Dolores,2022),模型能够通过课程学习使得各个智能体之间的决策进行更好的迁移,同时有利于将自动驾驶决策迁移到现实世界。 随着技术不断发展,其他的全自动课程学习方法也得到了发展,这些方法要求课程的生成只依赖于数据集、学生模型和任务目标。除此之外,元学习、图网络和超网络等优化方法与课程学习相结合也被证明在学生模型学习这方面具有巨大潜力。Narvekar等人(2017)提出以元学习与课程学习相结合,将课程设计制定为元马尔可夫决策过程。Peiss等人(2023)首次将课程学习应用于基于图神经网络的智能体,从而分解了这一复杂的学习任务。课程的子任务序列逐渐增加了智能体纵向和横向决策规划问题的难度,同时迁移到现实环境中并采取更谨慎的行为,提高决策迁移的效果。 知识蒸馏的概念最早由Hinton等人(2015)提出,其主要思想是小型学生模型向大型教师模型学习。该方法将知识在仿真环境中训练的教师模型迁移到在真实环境中部署的学生模型,以实现虚实迁移的作用。知识蒸馏作为虚实迁移的有效方法,已广泛应用于自动驾驶等多个人工智能领域(孙若禹和熊红凯,2023)。 知识蒸馏系统主要由3个部分组成:知识、蒸馏系统和师生结构。Gou等人(2021)从以上3个方面对知识蒸馏进行了调查,将知识类型分为基于响应的知识、基于特征的知识和基于关系的知识。基于响应的知识蒸馏主要是指学生模型直接模仿教师模型的最终预测。Saputra等人(2019)使用基于响应的知识蒸馏,构建了一个用于自动驾驶轨迹预测的师生结构,通过直接模仿教师模型的最终预测,将知识决策从仿真场景迁移到现实场景中。基于特征的知识蒸馏是一种通过利用特征层面的知识迁移来解决仿真和现实之间域差距的方法。Jang等人(2020)提出了一种带有蒸馏结构的深度强化学习方法来控制自动驾驶车辆的决策动作,使用特征知识的蒸馏解决了在资源受限的边缘系统进行域迁移的问题。基于关系的知识蒸馏是一种通过利用关系信息来减少域差距的方法。这种方法关注任务相关性、输出分布相似性以及样本级别的关系,使得学生模型能够更好地理解和适应现实域中的数据,以更好地迁移到现实环境中。Su等人(2022)提出了一种考虑概率和不确定性的决策预测模型,同时使用知识蒸馏技术来缩小以智能体为中心和以场景为中心的模型之间的性能差距。如图5所示,左侧是教师模型,每个智能体都以自身为中心,输入和输出都在以自身为中心的坐标系中;右边是学生模型,无需每一个智能体重复计算,只需将以学生和场景为中心的模型应用到全部场景,减少成本并提高迁移性能。 图5 基于知识蒸馏的概率运动预测模型(Su等,2022)从蒸馏系统来看,其可以分为离线蒸馏、在线蒸馏和自蒸馏。Tseng等人(2022)提出了一种离线蒸馏和多智能体强化学习结合的方法,该方法首先使用离线数据训练教师决策,然后在教师决策识别数据集中的“好”行为后,再创建单独的学生决策,有效地将仿真场景训练的决策迁移到现实场景;Houyon等人(2023)以在线蒸馏为基础,使用了持续学习方法来减少域差距的影响,并在自动驾驶的快速和慢速场景上都验证了该模型的优越性;Hu等人(2023)介绍了使用自蒸馏进行地面到空中的知识迁移,并提出了一种渐进式半监督学习框架实现智能体决策以进行虚实迁移。 迁移学习(Weiss等,2016)的主要思想是在虚拟的仿真域和现实域之间迁移数据或知识,从而提高现实域的学习效率,解决机器学习中不同域的数据标记所需的高成本和长时间的问题。 在自动驾驶中,现实场景的数据获取成本高昂,导致人们开始考虑在仿真环境中收集数据,并以合理的方式将其迁移到现实世界。Isele和Cosgun(2017)模拟交叉路口,并将学到的决策迁移到现实世界,表明迁移过程的稳健性。Kim和Park(2017)提出了一种端到端的顺序迁移学习方法,利用自车道的位置制定驾驶决策策略。该方法使用两次迁移,逐步进行环境和信息的迁移。由于该迁移方法考虑了场景完整上下文,所以更有利于减少有限探索造成的域差距。为了解决迁移过程中将预训练模型用到现实生活中并进行精细训练需要很长时间的问题,Liang等人(2022)提出了一种用于实时知识迁移的在线联邦强化学习的方法,智能体从头开始合作学习,用于进行自动驾驶端到端的避障决策训练。如图6所示,该框架要求智能体先在模拟器中进行端到端的训练,然后通过联邦学习服务器聚合所有智能体同时生成联邦模型,并在线迁移虚实环境中不同任务的知识,从而实现来自不同现实环境的智能体的异步学习和迁移。 图6 面向自动驾驶避障任务的联邦迁移强化学习方法(Liang等,2022)迁移学习在很多方面都有相应的应用,为了处理数据采集问题,Chiba和Sasaoka(2021)提出了一种能够提供明确监督数据的强化学习迁移方法,以自动驾驶的模型车为实验对象,改变学习模型的训练目标和实际驾驶决策课程,以实现虚实场景之间的决策迁移。迁移学习为多智能体深度强化提供了一个可靠的方向,Candela等人(2022)提出了一种迁移方法,能够有效地将多智能体自动驾驶策略转移到现实世界,通过将在模拟器中训练的策略迁移到现实世界中减少域差距。 研究人员为虚实迁移开发了其他几种可以有效降低域差距的技术,其中最经典的是系统识别和域随机化。 系统识别(Ljung,1998)技术能够更准确地表示真实环境中的复杂性和不确定性的挑战。在解决自动驾驶决策技术的域差距问题中,该方法将真实世界的数据用于估计真实系统的参数和动态。这种数据驱动的方法允许虚实迁移模型捕获现实场景中的复杂性和变化,从而提高模拟环境的保真度。 域随机化是一种解决虚实迁移中数据增强问题的方法。其主要思想是,在仿真环境中,引入照明条件、物体外观和物理参数等各个因素的随机变化,使得仿真环境变得更加多样化,包含了现实世界中可能遇到的更广泛的条件,从而减小虚实域之间的差距。目前,在自动驾驶领域已有工作使用域随机化技术来弥合仿真到现实场景的域差距。Niu等人(2021)将域随机化分为均匀域随机化和引导域随机化。均匀域随机化即域随机化的基本形式,在均匀采样的范围内随机每一个参数。Tobin等人(2017)首次在没有现实图像的情况下,通过域随机化将在仿真场景图像上训练的驾驶决策策略直接迁移到现实世界。引导域随机化是在域随机化基础形式上更为复杂的方法,主要思想是解决计算资源浪费以及现实世界中从未发生过的冗余训练的问题。之前大多数的域随机化方法会随机整个图像的全部特征,但在虚实迁移中,仍有一部分域不变的特征可以保留,以节省成本。为了解决这一问题,Huang等人(2021)提出的一种频率空间域随机化(freguency space domain randomization,FSDR)的方法,并应用于自动驾驶决策的迁移。如图7所示,该方法将原始图像转化为两种频率分量:保持域不变的频率分量(domain-invariant frequency components,DIFs)和随机化域变量的频率分量(domain-variant frequency components,DVFs)。通过这种方法,能够有效地保留域不变的特征,大大减少成本,也更有利于虚实迁移。目前,有大量研究使用引导域随机化解决自动驾驶中决策问题(Kontes等,2020;Kalapos等,2020;So等,2022;Béres和Gyires-Tóth,2023),以提高从模拟到真实决策迁移的稳定性。此外,域随机化与数字孪生的结合(Voogd等,2023)也被证明能够使自动驾驶决策更稳定地从虚拟世界迁移到真实世界中。 图7 基于频率空间域随机化的自动驾驶模型(Huang等,2021)
虚实迁移的方法已经逐步应用到自动驾驶的决策技术中,一定程度上解决了仿真到现实的域差距问题,但仍然受到一系列限制,如复杂环境难以进行计算实验和设计有效的模拟环境等。为了解决这些问题,王飞跃(2004b)提出平行智能的理论体系,该体系是由虚拟的仿真环境搭建的人工系统与现实的物理系统进行平行交互而形成的。在自动驾驶领域,该技术可以通过真实驾驶系统和人工驾驶系统之间的交互来产生驾驶决策,并利用两者的比较、学习和实验,实现对驾驶系统的管理和控制。同时,平行智能理论体系在交通、医疗、制造和控制等多个领域也取得了显著成效,如平行医院(王拥军等,2021)、平行电池(王飞跃和蒋怀光,2021)、平行矿山(陈龙等,2021)、平行光场(王飞跃等,2021)、平行皮肤(王飞跃等,2019)、平行眼(王飞跃等,2018b)等。相比于虚实迁移的方法,平行智能从更高的技术层面上处理虚实场景的关系,解决复杂建模的问题,并且更大程度地缩短了自动驾驶技术从仿真到现实场景之间的差异。 目前,在自动驾驶领域,平行智能发展出了多个体系分支,主要包括平行系统、平行学习、平行驾驶和平行规划。表2列出了有关基于平行智能的仿真到现实的决策技术相关工作。 表2 基于平行智能的决策方法
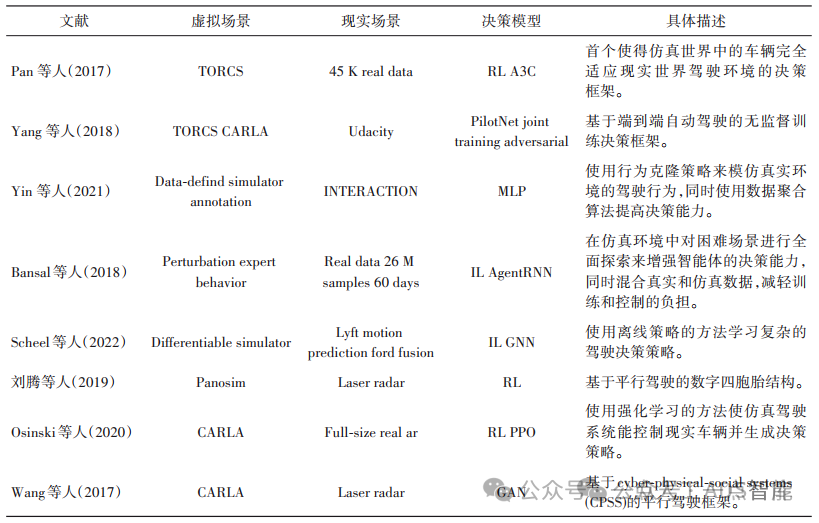
平行智能的基础是ACP方法,该方法由Wang等人(2004a)年提出。ACP即人工系统(A)、计算实验(C)和平行执行(P),它包括3个主要步骤:3)设置实际的物理系统和虚拟的人工系统进行交互,实现对复杂系统的有效控制和管理。其中,在自动驾驶领域,计算实验模块用于分析、预测驾驶系统以及制定决策,该模块可分为3个子步骤(Wang等,2016b)。1)学习和训练:ACP方法将人工系统的行为和物理系统的行为融合进行学习和训练,以解决人工驾驶系统与现实驾驶系统之间存在域差距的问题;2)测试和评估:通过虚拟人工系统和现实物理系统相互作用来提高自动驾驶决策的性能,同时进行生成和计算实验,并进行场景测试和评估,以提高自动驾驶规划模型的鲁棒性和安全性;3)管理及控制:将虚拟人工系统和现实物理系统进行并行交互及相互对照,实现管理和控制。除此之外,还有一些方法也旨在解决虚实迁移方法中复杂的建模问题,杨林瑶等人(2019)提出一种基于数字孪生的方法,实现物理系统向信息空间的数字化模型映射,通过使用系统各个部分的传感器来对实体进行数据分析和建模。不同于ACP方法,它的研究侧重于设计现实物理对象、过程和系统。而ACP方法更关注物理系统和人工系统之间的反馈和交互,将物理系统的行为映射到人工系统,充分发挥计算实验的优势。 在自动驾驶系统的研究中,存在从仿真到现实之间的域差距,以及难以精确建模来预测目标系统的问题。王飞跃(2004a)根据ACP方法的理论和体系正式提出了平行系统这一概念,能够有效地解决这些问题。平行系统是将一个或多个现实系统和虚拟的人工系统进行并行运行的系统,通过在系统中进行交互、分析和比较,获得最优的决策方案,对人工驾驶系统和真实驾驶系统预测和评估(王飞跃,2004b)。其中,在人工驾驶系统中策略的训练能从离线变为在线、从静态环境变为动态、从被动学习变为主动学习,由此可以减少人工驾驶系统和真实驾驶系统之间的差距。在实现自动驾驶的决策规划的过程中,通过建立人工系统来给车辆之间的交互提供便利,为实现自动驾驶决策模型的学习与训练、规划方案的实验与评估、虚实系统的管理和控制提供技术支撑。宁滨等人(2010)也利用平行系统解决了面向城市的轨道交通问题,形成一套处理城市轨道交通问题的平行控制和管理方法,进一步推动了平行系统的发展。 中国科学院王飞跃研究员在提出平行系统的思想后,又尝试将其扩展并引入到机器学习领域,建立了一种新型理论框架——平行学习(李力等,2017)。其主要思想是构建一个学习系统,让虚实两种系统通过反复的交互来进行决策指导和行为优化,使人工系统更好地从真实系统中学习经验,得到准确的系统映射,从而减小虚实之间的域差距。在自动驾驶系统中,以真实驾驶系统的数据作为输入,人工驾驶系统的参数作为输出,再将这两个驾驶系统分别按规律自行运行,并通过知识模型将其连接在一起。同时,记录真实驾驶系统从动作到状态的映射数据,将真实驾驶系统的数据提炼为经验,从而整合到人工驾驶系统。该过程降低了学习驾驶经验的数据构建成本,提升了平行学习系统的决策能力。 平行学习分为3个互相耦合的阶段:描述学习、预测学习和指示学习(李力等,2017)。其中,描述学习是指从大型人工系统的数据中提取知识和经验的过程;预测学习则能够建立从收集信息到未知信息的映射,是一个从观察到想象的过程;指示学习是在前两个过程的基础上进一步优化策略,从而确保系统具有更好的决策能力。在图8中,左边从状态S指向状态S'的箭头代表预测学习,利用提取到的经验以及真实系统的状态来预测人工系统的状态;右边从动作A'指向动作A的箭头代表指示学习,通过已有的策略来控制真实系统的决策并映射到人工系统,进一步优化决策的生成。整个过程利用预测学习和生成的虚拟数据来解决虚实之间的域差距问题,然后通过描述学习来提取经验,获取更优的现实场景的决策方案。 平行学习是处理自动驾驶决策系统从仿真到现实环境的合适框架,它通过虚实系统反复交互,使学习过程更加高效。针对自动驾驶的决策规划模块,平行学习解决了现存的两大难题:车辆动态约束和即时奖励难以确定问题(Chen等,2019),其解决方法是构建一个轨迹生成模型作为人工系统,并在系统中学习一个决策模型用来处理实际场景中决策规划的问题。然后,由人工系统生成的原始数据对决策模型进行改造,为决策生成提供依据,从而确定系统的即时奖励和车辆的动态约束。与传统方法相比,平行学习仅使用小部分数据就可以实现短期轨迹规划的高迁移性,极大地提升了决策的鲁棒性。除此之外,袁勇和王飞跃(2017)还将平行学习与区块链相结合,提出了平行区块链方法,为区块链增加了计算实验和平行决策功能。 为了在道路中实现车辆平稳、安全和高效的自动驾驶,Wang等人(2017)将平行系统理论应用到自动驾驶决策领域,并构建了由物理世界、心理世界和人工世界组成并进行自动连接的平行驾驶系统。该系统能通过建模,将真实的物理世界与虚拟的人工世界并行运行,在虚拟道路中实现完全自动化并过渡到真实世界中,从而减小域差距。在这个过程中虚实驾驶系统之间进行比较与学习,对系统进行实时更新和校准,以实现高效的决策规划。 平行驾驶框架中存在3个主要要素:物理车辆、人类驾驶员(human driver, HD)和驾驶员认知(driver cognition, DC)。根据ACP方法,可以将这3个道路驾驶元素自然地投射到3个平行世界中,构建出基于CPSS(cyber-physical-social systems)的平行驾驶框架,如图9所示。图9展示了3个层次的平行世界:物理(第1层)、心理(第2层)和人工(第3层)。在平行驾驶中,人工世界由IIIa和IIIb两层组成。IIIb是指CPSS服务层,包括人、地点和技术;IIIa是指专用的驾驶层,另外增加了人工驾驶员和人工车辆这两个专门的驱动层,构成了ADAV(artificial drivers and artificial vehicles)模块。与此同时,给系统中的每辆车分配一个ADAV控制模块,利用该模块与人工世界和其他ADAV模块通信,并在物理世界操作车辆使其与人类驾驶员交互。图中序号1—13表示不同层次之间的信息和控制流动。这种基于CPSS的平行驾驶框架通过仿真和现实驾驶系统之间的交互,同时协同复杂多级的车辆系统和驾驶员,从而提供更安全的自动驾驶决策方案。 平行驾驶技术在自动驾驶领域得到快速发展,但仍然面临一些挑战,如没有考虑紧急的交通场景。针对该问题,Chen等人(2019)在平行系统的概念上,将仿真到现实、机器学习以及运动规划等技术结合,提出了平行规划方法。该方法从人工生成的虚拟紧急交通场景中学习如何躲避障碍物,并在实时交互的场景中进行实验。通过虚实系统之间相互作用、相互反馈和相互引导,对比分析可能的方案,并用于决策建议。如图10所示,分别从真实和人工的驾驶场景中收集样本来训练规划模型以优化决策方案,再应用到实际驾驶场景生成不同的潜在紧急情况。其中,规划模型可以从真实和人工驾驶场景中学习驾驶策略和知识,并针对不同的虚拟紧急场景生产不同的决策方案,使之在紧急情况发生时做出及时反应。此外,为了更好地进行平行规划和决策,自动驾驶车辆需要增强在不同环境下的感知能力,研究人员提出了平行视觉(李轩和王飞跃,2021;张慧等,2021)和平行雷达(Liu等,2022)等方法。 图10 平行规划方法的框架(Chen等,2019)
模拟器是一种虚拟的仿真环境,它能够模拟特定的硬件、软件或环境,以便智能体可以在仿真世界中体验实际的操作或情境。在模拟环境中训练自动驾驶模型是仿真到现实方法中的一个重要环节。通过模拟的方式能够解决在现实世界中直接训练需要大量成本,以及罕见事件无法在真实场景中有效获取的问题。 模拟器的发展历程可以追溯到20世纪早期,早期的模拟器主要用于模拟物理,以帮助研究人员理解和优化各种机械系统。随着科技不断发展,一些模拟器基于具有渲染能力的游戏引擎被开发,如,Unreal、Unity等。随后,模拟器广泛用于自动驾驶领域,如CarSim(Benekohal和Treiterer,1988)、CarMaker(Ziegler和Höpler,2011)和Torcs(Wymann等,2015)。但这些模拟器对人物和天气等控制程度有限,没有考虑到复杂的环境设置、模拟车辆以及交通环境等因素。为了仿真出逼近真实环境的模拟环境,一些自动驾驶环境模拟器应运而生。这些模拟器主要是基于机器人模拟器改进而来的仿真环境,在单位层面,例如车辆模型、行人建模上可以实现更多细节,对传感器的精度也较高,但是对于环境等三维场景框架实现不够逼真,如Gazebo(Koenig和Howard,2004)。近年来,一些高保真的模拟器也已经被开发用来作为自动驾驶的虚拟环境,如SUMO(Krajzewicz等,2012)和AirSim(Shah等,2018)。此外,OpenScenario作为实现自动驾驶动态场景的标准已经得到了广泛的应用。一些经典的模拟器可基于OpenScenario构建自动驾驶任务的驾驶场景,如CARLA(Dosovitskiy等,2017)和LGSVL(Rong等,2020)等。目前,还有一些模拟器旨在解决自动驾驶强化学习中的泛化问题,如MetaDrive(Li等,2023)等。表3统计了常用的自动驾驶模拟器及其特点。 表3 主要的自动驾驶模拟器

目前,有关仿真到现实的自动驾驶决策技术研究已经取得了重大的进展。但是,为了实现更安全和更有效的自动驾驶决策,仍然需要进一步克服困难和挑战。这些挑战主要来自以下4个方面: 1)缺乏通用标准和方法。目前,虚实迁移的方法大多是针对某一个特定问题进行研究的,缺少通用的标准和方法解决虚实迁移的问题,也缺少明确的变量来揭示和量化域差距。如在域随机化中,研究人员倾向于用实例去研究该增加什么随机量有利于仿真到现实迁移(Pouyanfar等,2019;Huang等,2021),但是很难有一个变量来明确量化域差距,难以有效设计准确模拟和正确的随机化分布。因此,建立通用标准和方法,量化域差距,是目前仿真到现实领域的一个重要问题。 为了解决这一问题,研究人员可以引入跨领域学习的方法来提供一个通用的方法与标准。通过从不同任务和场景领域中学习知识,以提高决策技术在不同任务、不同场景上的泛化性能。同时,可以利用共享的知识和特征,使模型在不同任务和场景之间实现迁移,并减少对特定任务和场景的依赖。此外,如果能够描述和量化域差距,不仅能可视化该任务的有效性,还能在不同的技术之间直接进行比较。同时,域差距也可以直接作为优化目标,提高跨域决策性能。 2)模型的不可解释性。虚实迁移和平行智能作为仿真到现实迁移的方法,在解决自动驾驶各种问题中得到了很好的应用。如十字路口的规划决策(Isele和Cosgun,2017;Qiao 等,2018)、避障决策(Akhauri等,2021;Shen等,2022)和高速入口坡道的决策(He等,2023b)。但是大多数现有的虚实迁移和平行智能方法都是基于深度神经网络,缺乏可解释性。在自动驾驶领域中,安全、可靠的迁移是一个很重要的问题,当决策训练中出现不安全行为时,需要模型具备可解释性。因此在虚实迁移和平行智能方法中提供一个具有良好解释性的方法是一个巨大的挑战。 模型的可视化是近年来深度学习的一个重要研究方向,它可以帮助深度神经网络的研究人员理解网络的内部机制,因此将该技术用于仿真到现实模型的方法中,能帮助理解模型对于不同域的决策规则和重要特征的关注程度。此外,许多研究人员致力于开发深度神经网络的可解释性,使用分层模型以及与模块化方法相结合的方法,在某种程度上也可以为仿真到现实的模型提供可靠的解释。最后,使用集成模型解释技术也可以帮助理解模型在不同域上的行为差异。 3)数据采集的一致性问题。数据是基于机器学习方法的基础,训练虚实迁移和平行智能的模型,都需要海量的、多样化的样本数据。然而,由于驾驶场景复杂多变,在采集数据,特别是现实场景的数据时,往往受硬件设施、道路结构、天气和地形等因素的影响,造成数据缺乏一致性,从而导致数据、信息无法与任务和决策准确、及时、在线地整合在一起,难以构建虚实之间的映射关系。因此,数据采集的一致性,是目前仿真到现实的自动驾驶中一个亟待解决的问题。 在数据采集方面,研究人员可以建立多种不同智能实体之间语义层次的联结,以知识协同的方式在采集的原始经验数据中实现主动采集、知识获取、知识交换的全自动化过程,实现各智能体所拥有的知识与经验的互联互通,降低数据采集带来的限制,解决数据缺乏一致性的问题。此外,平行智能系统也需要建立更一致的数学模型,使系统能自动处理这种数据差异性,解决处理大规模复杂数据和任务的难题。 4)对硬件和算力要求高。近年来的研究成果表明,平行智能技术可以显著提高许多自动驾驶任务的能力,但是也仍然面临一些算力和硬件上的挑战。随着自动驾驶计算规模的扩大和功能需求的增加,平行智能系统需要不断地满足日益增长的计算规模以及软硬件复杂程度的要求。此外,多单元并行计算会导致计算节点间的通信开销占用大量计算资源,这需要设计高效的协作机制来协调智能系统与人类操作员之间的交互。 为了满足上述要求,一方面要求研究人员提供更高效和特定化的硬件,以满足不断增长的算力需求,同时配备足够的计算资源和存储空间以支持多个智能系统同时运行和交互;另一方面,需要开发具备自适应计算能力和智能的资源管理系统,使平行智能技术的计算资源能够根据任务需求动态分配和调整。此外,平行智能系统还需要有良好的扩展性,以确保能更高效地处理复杂多变的驾驶场景。
传统的自动驾驶决策技术往往依赖于现实世界的数据和场景,但直接在现实世界获得数据存在高风险和高成本的问题。为了解决这个问题,仿真到现实的方法成为一种很有潜力的技术。 本文首先通过虚实迁移和平行智能两个方面综述了仿真到现实的自动驾驶决策技术的研究进展和背景,然后详细介绍了虚实迁移和平行智能在决策中的作用。在虚实迁移方法中,主要依据不同类别的方法介绍了相关的决策迁移应用;在平行智能中,主要介绍了平行智能的分支以及在自动驾驶中的相关应用。随后,介绍了相关自动驾驶的模拟器及其特点。最后,本文提出了虚实迁移和平行智能在自动驾驶决策技术中的挑战与未来的发展趋势。 声明:除文内特殊声明外,本公众号内所有文章编写或转载的目的仅用于学习和交流,不予以商用,不代表本号观点及立场。本公众号内资讯及正文引用图片均由个人公众号 ADS 智库六耳基于官网或公开信息梳理或引用。本公众号所引用及转载内容版权均归原作者所有,凡是注明来源 “ XXX ADS 智库 ” 或作者为 “ XXX 六耳、XXX ADS 智库 ” 的文章转载或引用时请注明来源 ADS 智库。若有版权或其他任何问题请联系六耳( 微信号:adas_miao ),本号将及时处理。