

事情起因是这样的!下午的 Family 群里,有家人和小鹿说 DeepSeek 的新模型性能不错!但是涨价了!
哦?Deepseek 可是国产大模型界的拼多多啊。这次推出即爆火的 V3 价格翻了一倍不止。
DeepSeek V3 的 API 官方定价:
输入:2 元/M tokens命中缓存0.5元Mt
输出:8 元/M tokens2025 年 2 月 8 日前,
输入:1 元/M tokens命中缓存0.1元Mt
输出 :2 元/M tokens
不过,这个价格依旧只相当于 Claude 3.5 Sonnet 费用的 1/53(后者每百万输入 3 美元/Mt、输出 15 美元/Mt)。
一起看下 Deepseek-V3 涨价涨的值不值 ~
模型表现与 Claude 3.5 Sonnet 相当
这次发的新模型 DeepSeek-V3 采用了 671B 参数 MoE 架构,配备约 37B 激活单元,在高达 14.8T 个高质量 Token 上完成了预训练。
DeepSeek-V3 相比上一代 V2 进行了大幅升级,仔细看
数学基准(MATH 500):取得了 90.2 的高分,领先 Claude 3.5 Sonnet 和 GPT-4o 超过 10 分。 AIME 2024 测试:领跑,比前代成绩飙升近 20 分。 代码能力(Codeforces 基准):达到了 51.6 分,比国外主流大模型高出约 30 分,刷新了该领域的 SOTA 水平。 软件工程(SWE-bench Verified):略显逊色,尚不及分数达 50.8 的 Claude 3.5 Sonnet。 多语言能力(MMLU-Pro):在多语言上的进步不算明显。 知识问答(GPQA-Diamond):仅次于 Claude 3.5 Sonnet。
和闭源比完,接着看看和开源主流模型比怎么样,“对手”包括 DeepSeek-V2 的基础版、Qwen2.5 72B 的基础版,以及 LLaMA-3.1 405B 的基础版:
总的来说,DeepSeek-V3 的基础版就像“开了挂”一样,性能全面超越了自家的 V2 和 Qwen2.5 72B。即使是面对参数量更大的 LLaMA-3.1 405B,DeepSeek-V3 在大多数测试中也毫不逊色,可以说是目前最强大的开源模型之一。
细看一下各项对比结果:
对比目前很火的中文开源模型 Qwen2.5 72B,DeepSeek-V3 的优势非常明显。V3 实际参与运算的参数只有 Qwen2.5 的一半,但在英文、多语言、写代码和解数学题这些方面,V3 都表现得更好。在中文能力上,除了 CMMLU 这个测试,V3 也都比 Qwen2.5 更强。 对比参数量巨大的 LLaMA-3.1 405B(“容量”为 V3 的 11 倍),DeepSeek-V3 在多语言、代码和数学方面的表现依然更出色。
一句话,DeepSeek v3 成为了大模型新的开源 SOTA ,超越了 Llama 3.1 405B,甚至可以与 GPT-4o、Claude 3.5 Sonnet 等闭源模型正面抗衡。
当然,还是老规矩。
官方的测试数据,我们从来只信一半。真正好不好,测了才知道。
来,先上一手的智商测试!
智商测试
先来测试一道智商题(误
嗯嗯!很满意 ~ 据说隔壁 Claude3.5 还是错着呢。
好了,来测一下真正的智商表现。
先测一道大家熟悉的编程题:
我想要 python 实现一段代码支持一个操作,就是将我在命令行里输入过的 query 按照时间顺序 cache 到本地的一个文件里和内存里,如果我在命令行里按方向键上或方向键下,就能切换到上一个输入的 query 或者下一个输入的 query(像使用 bash 那样)。如果按方向键左或右,则能够移动光标来编辑文字(而不是输入一个方向字符);移动光标或删除的时候,需要支持中文汉字删除,不能把汉字拆分成多个 char 去分别删除
不要在命令行里出现这种把方向键当做查询输入的情况,而是去解析方向键:
请输入搜索查询: ^[[A^[[A^[[B^[[B^[[A^[[B
看看 Deepseek v3 能否创造奇迹。
运行一下——
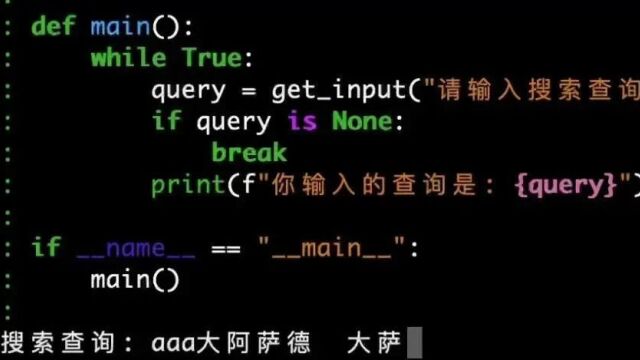
不是吧,这次竟然真的完美运行了!
而且代码非常的优雅干净,它用了一个 python 内置的库就直接解决了问题。相比之前,claude3.5 和 gpt4o 自己一顿 DIY 后还一堆 bug。
有可能,官方号称的编程能力跟 claude3.5 不相上下,是个低调谦虚的说法。
非常难的问题上,虽然不一定打得过 o1 满血版和 gemini 2.0 thinking,但编程能力比 gpt4o 和 claude3.5sonnet 强,从我们内部的测试来看,这句话是站得住脚的。
此外,官方号称,不仅编程,v3 在数学上也是领先其他模型一大截的,也就是MATH-500、AIME 2024、Codeforces,所以我就测测数学上是不是也一样牛。
北京大学与阿里巴巴的研究团队联合打造了一个专门用于数学竞赛的奥林匹克评测基准——Omni-MATH,就用它来测!
第一题:
题目我没看懂,但是答案很明确,是 Yes。
V3 的答案是 No.
嗯?v3 失误了吗?
再来一道!
题目依旧看不懂,截图在这。
我让 V3 把答案翻译成中文,并和它的回答比较是否一致,呃,又错了。。。

可能是题目难度过大了。我换了一道高中数学题,
降了难度后,它终于答对了。
另外,虽然根据官方的说法,Deepseek v3 是个纯文本模型,但我强行在 Deepseek 官网上传了这张大家熟悉的图后——
标准答案:ADBAADAB
结果无意间发现——
竟然答对了 6 道!
而且 o1 和 gemini thinking 都是新一代推理范式的模型,Deepseek v3 还是之前的老范式。
我不清楚官方是先把这张图经过 OCR,丢给了 v3,还是说这种有图片上传的题会直接路由到之前的 Deepseek VL2 视觉模型。
但,无论哪种情况,我都得说一句——
有点过于牛逼了。
对于一些难度很大的数学竞赛题,可能还是要用类 o1 范式的模型去解决。但一些简单的数学题(高中及以下),Deepseek v3 可能就能搞定了。
总的来说,Deepseek v3 的智商我觉得是非常在线的,尤其是,这还没有在推理阶段做 scaling up。
情商测试
情商测试来自于前两天的这个推文——
结果,Family 群里有家人说 V3 没做出来情商题——
所以我准备对 Deepseek v3 加测一下情商表现!
Round 1
得!Deepseek v3 你果然情商不在线。
Round 2
那再问问爱不爱人类吧:
行吧,足够安全,但也因此牺牲了情商。
Round 3
我再问问掉水里先救谁!
好吧,还是没有情商可言,只有满满的安全感 qaq。
通过本文的简单测评来看,Deepseek v3 模型可以说——
智商牛逼,但情商不存在...
有趣的技术细节
除此之外,DeepSeek 提供了关于 v3 的技术报告:
官方链接:
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
我扒了下,发现有很多有意思的技术细节。
首先是数据,相较于 DeepSeek-V2,DeepSeek-V3 提高了数学与编程样本的比例,并将多语言覆盖范围扩展到英语和中文之外。
然后是超参数,DeepSeek-V3 采用了 61 层 Transformer。除前三层外,所有 FFN 均被 MoE 层 替换,每个 MoE 层包含 1 个共享专家和 256 个路由专家;其中,每个 token 会激活 8 个专家,最多分配到 4 个节点。
还有长上下文扩展 ,为实现长上下文处理,DeepSeek-V3 在预训练后采用 YaRN 技术进行扩展,并分两个阶段进行额外训练,每个阶段 1000 步,逐步将上下文窗口从 4K 扩大到 32K,最终达到 128K。
模型训练成本令人发指
Deepseek 研究团队明确的保证:
DeepSeek-V3 仅用 2048 块 GPU、历时两个月完成训练,总花费约 557.6 万美元。
这个训练成本低到什么程度呢:
相当于 Claude 3.5 Sonnet 的 9%。
大神 Karpathy 也在 X 上盛赞 DeepSeek-V3 的高效:
“达到这种能力通常需要上万 GPU,而 DeepSeek-V3 仅用少量资源就实现了。对比 Llama 3 405B 的 3080 万 GPU 小时,DeepSeek-V3 只用了 280 万,计算量大幅减少。
这并非意味着不需要大型集群,而是要重视资源利用和算法优化。DeepSeek-V3 的表现若能得到普遍认可,将有力证明资源约束下也能做出优秀成果。”
结语
在过去一段时间里,大语言模型的社区对于算力的追逐往往陷入一种“集群越大、训练耗时越短、模型越强”的思维模式。
最近 OpenAI 被爆料在训练 GPT-5 是遇到资源和数据的限制而导致迟迟做不出来...
而 DeepSeek-V3,则成功通过深度优化的模型架构、训练策略、数据筛选和工程流程,同样能换来大幅度的性能增长和成本压缩——甚至让那些盲目投入十万卡、数千万 GPU 小时的项目看上去有些“浪费”......
从此,大模型社区多了一句论调:
从 Deepseek v3 来看,决定性胜负手不再只是显卡数量。
但我还是忍不住想问——啥时候国产模型能有情商的概念?