LLaVA-CoT 是一种新型的视觉-语言模型(VLM),由来自北大、清华、阿里达摩院和莱赫大学的研究人员共同开发,它通过自主的多阶段推理来处理复杂的视觉问题解答任务。

与传统的VLMs不同,LLaVA-CoT能够独立地进行总结、视觉解释、逻辑推理和结论生成的顺序阶段,这种结构化的方法使其在推理密集型任务中表现出色。研究者们还创建了LLaVA-CoT-100k数据集,该数据集整合了多种视觉问题解答样本,并提供了结构化推理注释,以支持模型的训练。此外,他们提出了一种推理时阶段级别的束搜索方法,这种方法在模型推理时能够有效地扩展性能。LLaVA-CoT模型、代码、数据集已上线始智AI-wisemodel开源社区,欢迎大家前去下载和体验。https://wisemodel.cn/models/KevinTHU/Llama-3.2V-11B-cot
https://wisemodel.cn/datasets/KevinTHU/LLaVA-CoT-100k
https://wisemodel.cn/codes/KevinTHU/LLaVA-CoT
LLaVA-CoT 是一种创新的视觉语言模型,专注于多模态推理任务中的系统性和结构化挑战。传统视觉语言模型往往在复杂推理任务中表现不佳,其原因在于缺乏系统的多阶段推理能力和清晰的任务分解能力。
而 LLaVA-CoT 则通过分阶段推理的方式,明确每个阶段的目标,逐步完成推理任务。模型的设计不仅强调推理的精确性,还注重推理过程的透明性,使得用户可以清晰地理解模型的每一步逻辑。
LLaVA-CoT 的推理被分为四个阶段:总结(Summary)、图像描述(Caption)、逻辑推理(Reasoning)和结论生成(Conclusion)。在总结阶段,模型会概述问题的主要目标以及解决问题的初步方法,为后续推理奠定基础。接着,模型在图像描述阶段提取图像中的关键特征,确保输入的多模态数据被充分理解。随后,逻辑推理阶段则根据前两步信息进行逐步分析,层层递进得出可能的答案。最后,结论生成阶段根据前述推理提供最终回答,确保输出结果简洁而准确。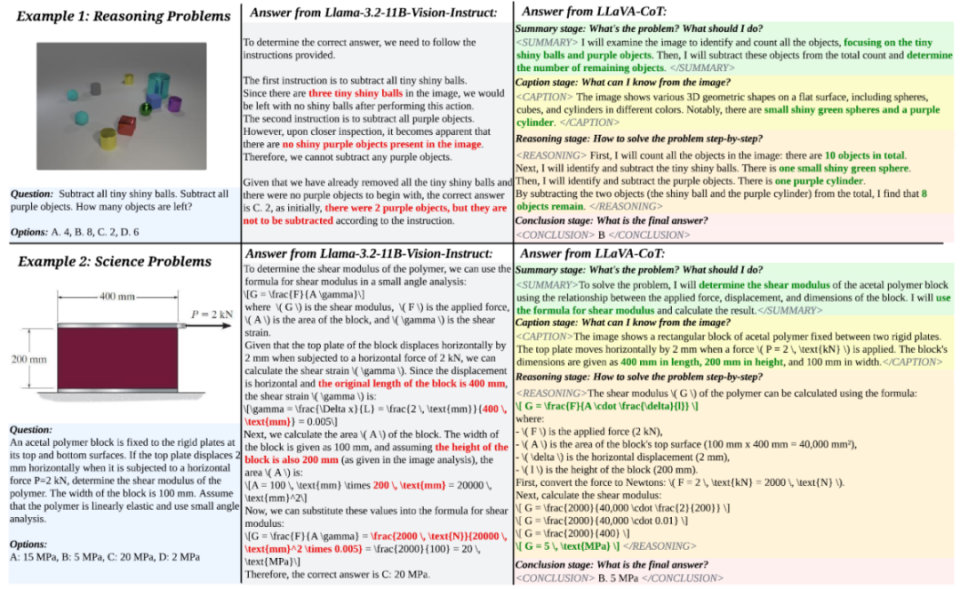
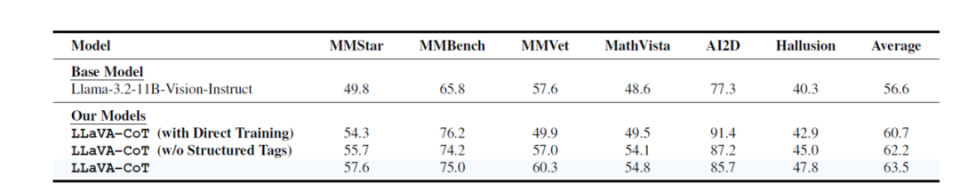
这一分阶段的推理方式,与传统的直接预测或链式推理(Chain-of-Thought)形成鲜明对比。传统方法通常依赖于模型自身的推理能力,LLaVA-CoT则通过结构化的推理框架,显著提升了模型的自组织能力,使其在复杂任务中能够始终保持逻辑一致性。这种设计不仅提升了任务的可解释性,还大幅改善了推理的准确性。为了支持 LLaVA-CoT 的多阶段推理能力,研究团队专门构建了 LLaVA-CoT-100k 数据集。该数据集整合了多个视觉问答(VQA)基准的数据,包括 MMStar、MMBench 和 ScienceQA 等。这些数据涵盖了科学推理、数学计算和图像理解等多种任务场景,共包含 9.9万对图像问答样本。与传统问答数据集不同,LLaVA-CoT-100k 的每个样本都被标注为四个推理阶段,以指导模型分步骤理解和解决问题。训练过程中,LLaVA-CoT 使用了Llama-3.2-11B-Vision-Instruct 作为基础模型,并通过监督微调(Supervised Fine-Tuning)完成微调。训练采用全参数微调方式,在 8 张 H100 GPU 上完成。每个阶段的推理都通过明确的标记(例如 <SUMMARY> 和 <REASONING>)加以区分,模型能够基于这些标记实现独立的任务分解与组织。推理阶段的性能进一步通过 stage-level beam search 的方法优化。这种方法在每个推理阶段生成多个候选答案,并通过模型筛选最佳结果后进入下一阶段。这种策略相比传统的 sentence-level beam search 更加高效,避免了逐句验证的低效问题,同时也克服了 Best-of-N Sampling 方法中生成整段答案的不准确性。实验结果表明,stage-level beam search 方法可以显著提升模型的推理准确性和稳定性。LLaVA-CoT 在多个视觉语言基准测试中表现出了卓越的性能。在六个广泛使用的多模态推理基准(如 MMStar、MMBench 和 MathVista)中,LLaVA-CoT 的平均分数比基线模型 Llama-3.2-11B-Vision-Instruct 提高了 8.9%。
模型的表现超越了许多更大的开源模型(如 Llama-3.2-90B-Vision-Instruct),甚至在某些基准测试中超过了 GPT-4o-mini 和 Gemini-1.5-Pro 等闭源模型。通过将推理过程分解为清晰的四个阶段,LLaVA-CoT 能够在模型慢思考方面实现突破。
此外,消融实验进一步验证了模型的设计。移除推理阶段标记(例如 <SUMMARY> 和 <REASONING>)后,模型在多个任务中的表现明显下降,这表明分阶段的结构化推理对提升模型能力至关重要。同样,如果仅使用原始问答数据而不采用 LLaVA-CoT-100k 数据集,模型的推理能力则会更加显著减弱。这些结果表明,LLaVA-CoT的多阶段推理框架为复杂多模态推理任务提供了强有力的支持。
Wisemodel社区支持直接通过模型镜像创建在线体验,在Llama-3.2V-11B-cot模型详情页点击“在线部署-部署在线体验”按钮。
然后选择和确认计费方式,这里选择按量-手动停止的计费方式,大家也可以根据自己的需求选择计费方式。
提交订单之后,应用已经进入启动中的状态,正常情况下大概等待1分钟左右就正常运营,进行在线体验了。