在端侧设备模型研发领域,一直面临着诸多难题,如设备算力有限,难以承载大规模参数模型高效运行,导致模型在处理多模态数据时速度迟缓;不同模态数据融合困难,易出现信息错配或丢失,致使理解精度欠佳。
无问芯穹刚发布的全球首个端侧全模态理解开源模型Megrez-3B-Omni针对性地给出了解决方案。Megrez-3B-Omni基于无问大语言模型Megrez-3B-Instruct扩展,同时具备图片、文本、音频三种模态数据的理解分析能力,采用专为手机、平板等端侧设备定制的 30 亿参数黄金尺寸,主干网络参数规模精简至 2.3B,在有限算力下实现了精度超越上一代 14B 模型,最大推理速度比同精度模型快 300%。此模型在众多测评基准中表现卓越,与同类型的 VITA ( based on Mixtral 8×7B) 、Baichuan-Omni-7B 等模型对比,在主流基准测试集上毫不逊色,还支持多轮对话里语音与文本输入自由切换,为端侧全模态理解应用落地提供了高效可行的基础模型支撑。Megrez-3B-Omni、Megrez-3B-Instruct的模型均已上线始智AI-wisemodel开源社区,欢迎前去体验。https://wisemodel.cn/models/Infinigence/Megrez-3B-Omni
https://wisemodel.cn/models/Infinigence/Megrez-3B-Instruct
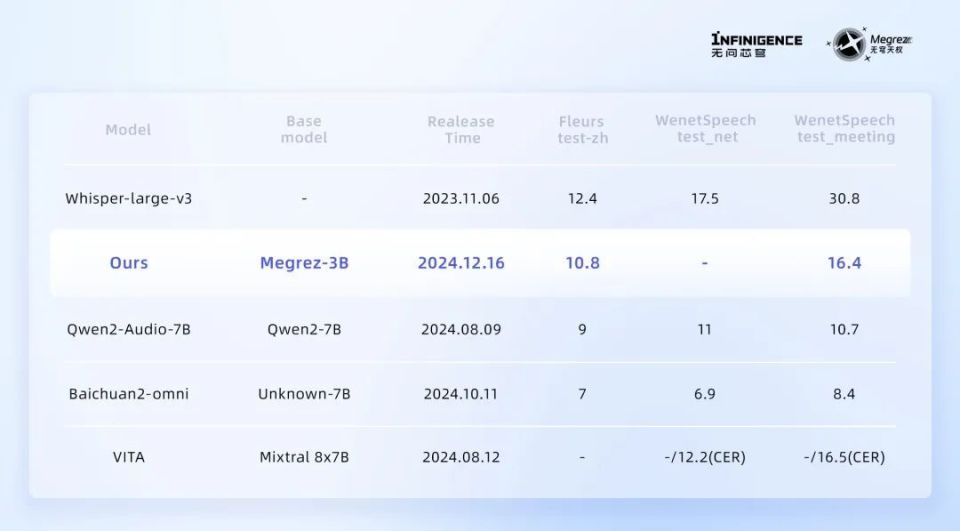
在图像理解方面,Megrez-3B-Omni 作为一个体积仅为3B的模型,其综合性能表现可以全面超过34B的庞然大物,是目前OpenCompass、MME、MMMU、OCRBench等多个主流测试集上精度最高的图像理解模型之一。
与此同时,Megrez-3B-Omni 在场景理解、OCR等任务上也具有良好表现,能够准确洞察和分析任意比例尺寸图像中的场景内容,并高效地从中提取文本信息,且无论是模糊的印刷体还是复杂的手写字,都能够轻松识别。在文本理解方面,作为全模态理解模型,Megrez-3B-Omni 没有牺牲模型的文本处理能力,将上一代14B大模型的优秀能力压缩至3B规模,显著降低了计算成本、提升了计算效率。
在C-EVAL、MMLU/MMLU Pro、AlignBench等多个权威测试集上更是取得端上模型最优精度,在文本理解方面确立了全球领先地位。同时,以更少的资源消耗,实现了更高的性能输出,为端侧设备的智能化提供了进一步突破精度与速度边界的全新可能。

在语音理解方面,Megrez-3B-Omni的效果比肩行业主流方案。Megrez-3B-Omni不仅支持中文和英文的语音输入,还能够处理复杂的多轮对话场景,更能支持对输入图片或文字的语音提问。
用户就任意模态内容,发出语音指令,Megrez-3B-Omni就能根据语音指令直接响应文本,实现多轮对话中语音与文本输入的自由切换,让用户可以通过更少动作与模型展开更直观、自然的交互。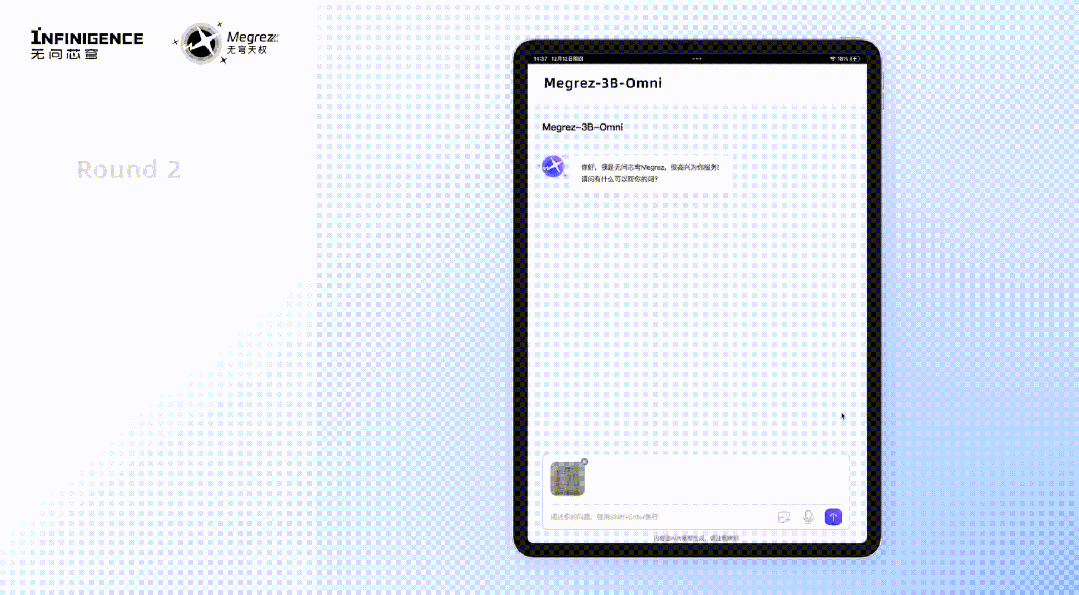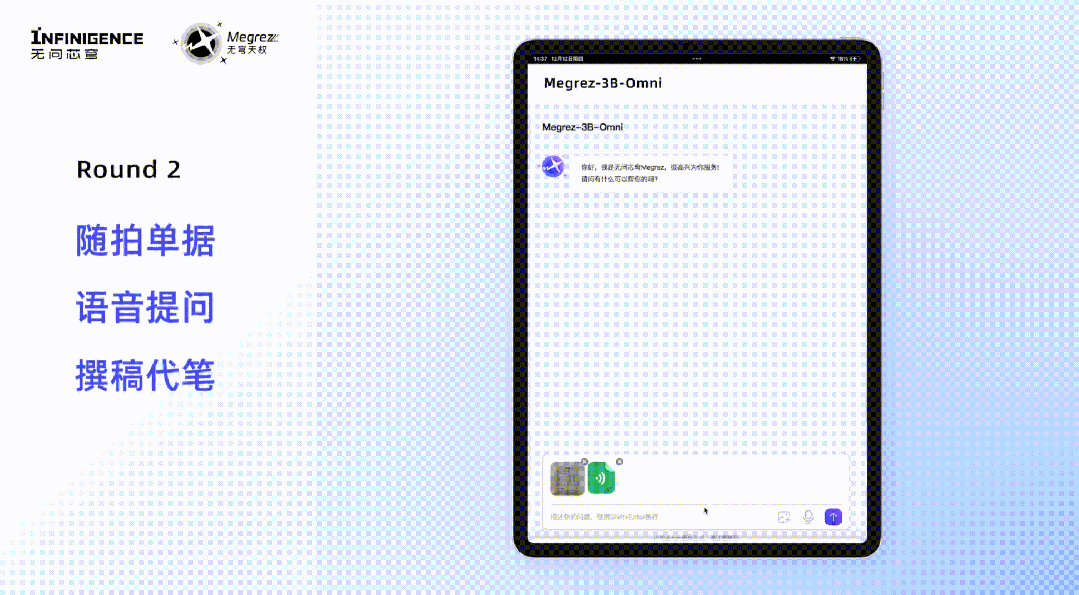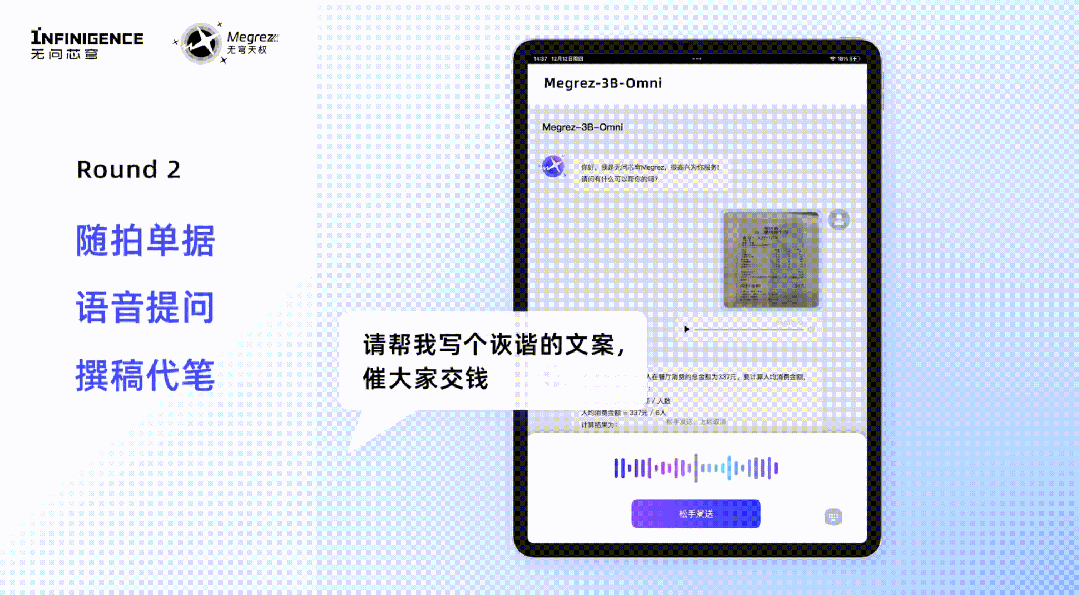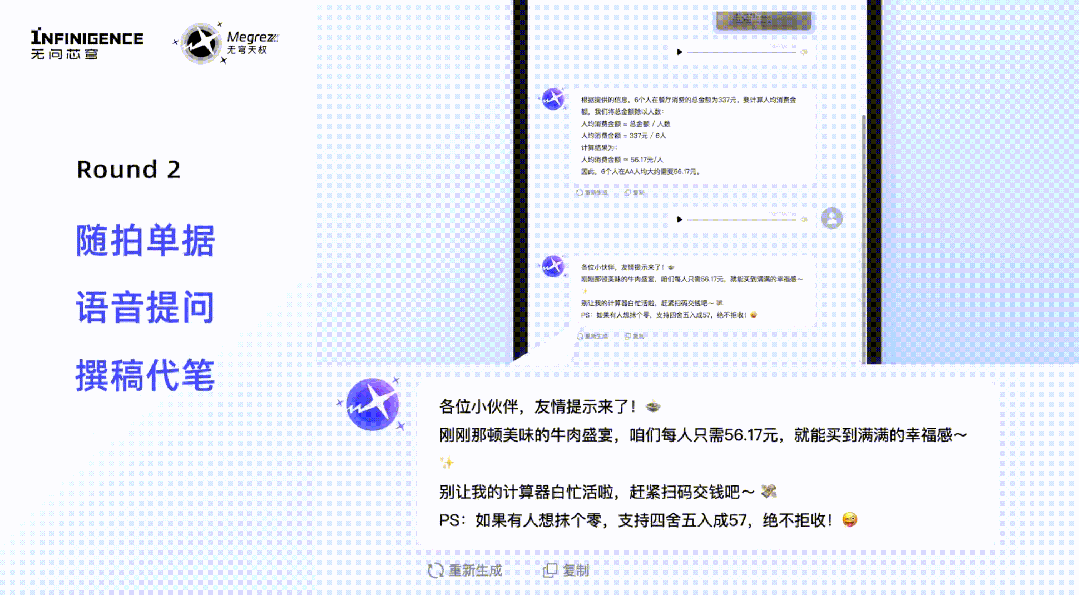 模型的规模并不是决定其速度的唯一因素,因此模型小并不一定就意味着速度快。凭借对硬件特性的深入理解与利用,Megrez-3B-Omni 通过软硬件协同优化策略,确保了各参数与主流硬件高度适配,以实现硬件性能的利用最大化。与上一代及其他端侧大语言模型相比,单模态LLM版本的Megrez-3B-Instruct 在推理速度上取得了显著提升,最大推理速度可以领先同精度模型300%。Megrez-3B-Instruct这次还特别提供了WebSearch功能,这一功能使得模型能够智能地判断何时需要调用外部工具进行网页搜索,辅助回答用户的问题。用户得以构建属于自己AI搜索,通过网络获取最新信息,克服小模型的幻觉问题和知识储备不足的局限。有时,模型通过搜索网页可以更全面地完成回答,而其他时候,模型自身已具备足够的知识来独立解决问题,过多的搜索调用可能会降低推理速度和效果。Megrez-3B-Instruct 通过在搜索和对话之间智能切换,避免了过度依赖搜索或完全不调用搜索的问题。除了可以自动决策工具调用时机之外,Megrez-3B-Instruct 还具备上下文理解性能优异、可提供带参考信息的结构化输出等优势。
模型的规模并不是决定其速度的唯一因素,因此模型小并不一定就意味着速度快。凭借对硬件特性的深入理解与利用,Megrez-3B-Omni 通过软硬件协同优化策略,确保了各参数与主流硬件高度适配,以实现硬件性能的利用最大化。与上一代及其他端侧大语言模型相比,单模态LLM版本的Megrez-3B-Instruct 在推理速度上取得了显著提升,最大推理速度可以领先同精度模型300%。Megrez-3B-Instruct这次还特别提供了WebSearch功能,这一功能使得模型能够智能地判断何时需要调用外部工具进行网页搜索,辅助回答用户的问题。用户得以构建属于自己AI搜索,通过网络获取最新信息,克服小模型的幻觉问题和知识储备不足的局限。有时,模型通过搜索网页可以更全面地完成回答,而其他时候,模型自身已具备足够的知识来独立解决问题,过多的搜索调用可能会降低推理速度和效果。Megrez-3B-Instruct 通过在搜索和对话之间智能切换,避免了过度依赖搜索或完全不调用搜索的问题。除了可以自动决策工具调用时机之外,Megrez-3B-Instruct 还具备上下文理解性能优异、可提供带参考信息的结构化输出等优势。
目前,这些能力已集成于Megrez-3B-Instruct模型中,用户可以通过System Prompt 自由切换,同时享受到高精度模型推理能力与智能WebSearch 调用收益。相较于云端大模型,端侧模型需要在资源有限的设备上快速部署、高效运行,对降低模型计算和存储需求提出更高要求。Megrez-3B-Omni是一个能力预览,接下来还将持续迭代Megrez系列,提升自动化水平至“edge device use”效果,让用户只需要给出简单的语音指令,就可完成端设备的设置或应用操作,并将它作为“端模型+端软件+端IP”端上智能一体化解决方案的重要构成推向市场。目前,无问芯穹就该一体化方案已与多家知名智能设备和终端芯片厂商展开合作。除端侧全模态理解模型外,还有端上推理软件和IP设计方案,不仅支持CPU、GPU和NPU 的同时推理,更能通过跨越软硬件层次的系统优化,额外带来最高可达70%的性能提升,最大化端侧硬件性能的利用。在这种软硬件协同优化思路下,更多电脑、平板、手机、眼镜等端设备有望迎来更佳效果的智能升级。首先在wisemodel上创建一个单卡A5000和3090的开发环境,选择基础开发镜像,选择模型文件/llm/Infinigence/Megrez-3B-Omni,填写好基本的信息,直接下一步,确认计费方式之后直接提交订单,开发环境就开始创建了。

开发环境创建好之后,通过notebook或通过SSH登录到开发环境上进行部署相关的操作。SSH登录到开发环境之后,先从github上把Megrez-3B-Omni的代码拉到开发环境。安装好所需的库之后,先修改模型代码,修改为以下2个地方:
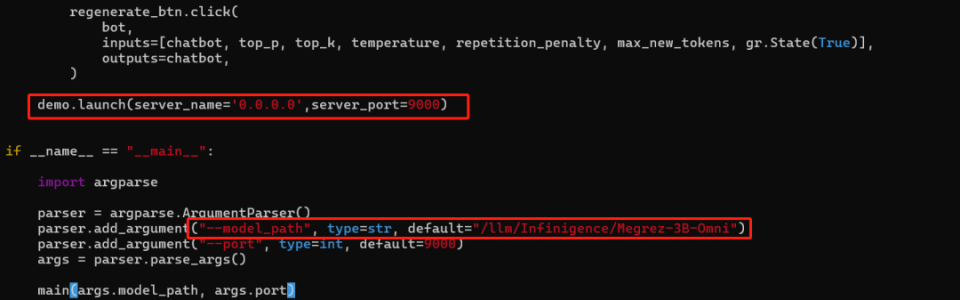

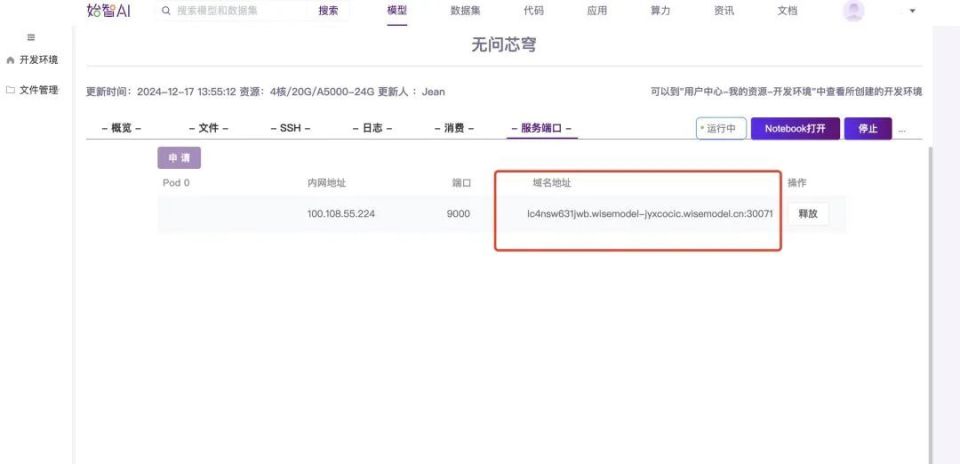
模型部署的基本工作就完成,成功之后,回到开发环境详情的页面申请一个服务端口和域名地址。把申请好的域名地址复制到浏览器里,demo正常运行,就可以开始体验模型服务了。
Wisemodel社区支持直接通过模型镜像创建在线体验,在Megrez-3B-Omni模型详情页点击“在线部署-部署在线体验”按钮。
然后选择和确认计费方式,这里选择按量-手动停止的计费方式,大家也可以根据自己的需求选择计费方式。
提交订单之后,应用已经进入启动中的状态,正常情况下大概等待1分钟左右就正常运营,进行在线体验了。