来源:本文由 ADS 智库整理自大侠5791、36Kr及零号位等网络信息 | 首图图源:网络
全文 4000+ 字,预计阅读 20-25 分钟
NOA 全称为 Navigate on Autopilot ,通常被业界称为“领航辅助驾驶”或“高阶智能驾驶”。不同企业的叫法略有不同,如小鹏称为 NGP,理想和特斯拉称其为 NOA,蔚来早期叫 NAD,长城魏品牌则称其为 NOH,但本质上它们都是NOA。按应用场景分,NOA 分为高速 NOA 和城市 NOA。城市 NOA 系统是指自动驾驶功能融合导航系统,可以依据导航在复杂的城市道路中实现点到点的“导航辅助驾驶”。用户在导航上设置好目的地,车辆可在无需人为接管的情况下,全程辅助驾驶到达终点。
城市道路不同于高速道路,它的复杂程度比高速工况提升了几个数量级,行人、电动车、宠物、机动车、非机动车一起出现在城市道路上,存在各种突发情况,比如车辆的极限加塞、公交等大型车辆切入、电动车随意变道等,这些都增加了道路交通的不确定性,对于智能汽车的环境感知能力和数据处理能力都提出了极高要求。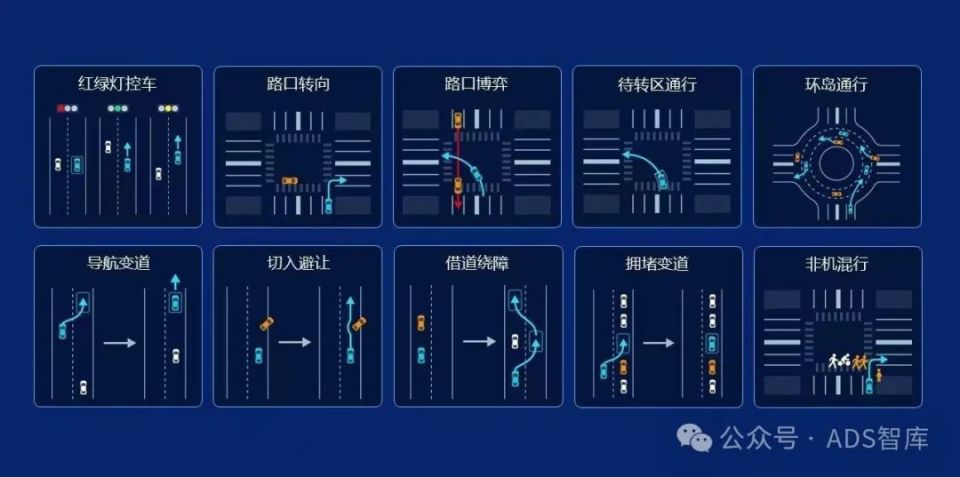
如下列出了具备城市 NOA 系统的智能车辆必须实现的功能场景,以供参考:
场景1(车速保持)
场景2(车道保持)
场景3(跟车行驶)
场景4(变道行驶)
场景5(并/换道行驶)
场景6(交叉路口行驶)
场景7(环形路口行驶)
场景8(前方车辆变换处理)
场景9(道路弱势目标避让)
场景10(障碍物避让)
场景11(U型掉头)
目前,各路玩家实现城市NOA的技术方案存在差异,要么是对城市NOA的技术路线理解不同,要么是虽然理解一致,但不同的技术实力导致技术路线实现的程度不同,例如小模型与大模型、有图与无图、纯视觉与多传感器融合等。
小模型与大模型的区别主要在于参数量的多少,以及模型的复杂程度。目前智能驾驶正在从以往的传统小模型方案,向端到端的大模型方案过渡。小模型是指参数较少、架构相对简单的AI计算模型,其优势在于资源需求少、实时性高、低功耗等。传统的智能驾驶算法架构包括感知、决策、规控等模块,每个模块有独立的任务,各自负责输出对应的结果,形成多个独立计算的小模型。传统的小模型方法能够让每个模块的计算结果都能有足够好的可解释性,在开发过程中能够独立优化,但由于小模型的参数有限,计算能力难以满足高阶智驾的要求,尤其是多传感器的大量数据处理、复杂场景中的路径规划等任务,因此需要提升模型的计算能力,保证高阶智驾的性能。另外,基于多个独立小模型的智驾系统,模块与模块之间的数据传输会存在损耗。以感知和决策模块为例,决策模块从感知得到的数据类型,都是基于现有资源提前定义好的,存在局限性;但由于真实交通环境的复杂性以及开发资源的限制,部分数据会得不到传输,比如前车转向灯亮起时,传统的感知小模型通常不会输出该信息,导致系统不能像人一样,“发现转向灯,并提前反应”。由于小模型在计算能力和数据传输方面的限制,端到端大模型成为城市NOA等高阶智驾的计算解决方案。端到端大模型是指从输入到输出的整体过程都由一个统一的、参数量多、计算能力极强的AI模型处理,中间没有显示的分模块步骤。与传统的智能驾驶算法架构不同,端到端大模型取代了此前用于感知、决策、规控的多个独立模块,输入的环境数据(摄像头、雷达数据等)直接送入模型,模型计算后,直接输出最终的控制指令(加速度、转角等)。端到端大模型不仅突破了传统小模型的算力限制和数据传输限制,更重要的是,能够通过大量的数据驱动来不断优化和改进系统的性能,而不需要过多依赖传统的规则代码。端到端去掉了规则主导的架构,完全交给神经网络主导,神经网络通过观察大量的数据,自我学习如何做出像人一样的驾驶决策。简单来说,传统小模型是让系统根据规则计算,而端到端大模型是让系统模拟人。不过,端到端大模型虽然优势明显,但也存在弊端,主要体现在系统的可解释性弱,以及对训练数据需求量极大。端到端大模型的内部架构复杂,其计算过程难以直观地理解,导致其计算结果难以解释,对于问题的复现、调试和解决,产生了挑战。由于大模型的计算处理过程,是通过大量数据训练得来的,因此对用于训练的数据的质量和数量都有较高的要求,包括多样化的道路环境、不同天气下各种工况的表现、各种类型的交通标志等。海量数据的获取、处理和应用,需要巨大的资源投入,研发成本很高。目前国内的端到端大模型势头正猛,已经成为城市NOA技术路线的必然趋势。不过,当前对于端到端模型的验证主要是开环验证,很少与外部环境产生交互,主要是验证输入和输出链路;想要实现方案的最终落地,需要经过大量真实场景的考验,从这个角度来看,国内端到端方案的实现和推广还有一段路要走。综合考虑小模型与大模型各自的特点以及当前的技术水平,通过组合的方式同时将小模型与大模型应用于城市NOA等高阶智驾,是合理可行的方案。例如,可以通过小模型对环境数据进行初步的处理与过滤,然后由大模型进行后续的进一步计算处理,这样能够充分利用大模型的高精度和计算能力,以及小模型的高效性,提供一套强大又灵活的智驾系统。
高精地图曾经一度是高阶智能驾驶的必备,但最近两年,行业内“去高精地图”的声音越来越响,小鹏、华为、毫末智行等多家主机厂与智驾方案商,纷纷朝着“重感知,轻地图”的无图技术路线发展。所谓有图,也就是以往搭载高精地图的方案,高精地图作为一种先验信息,可以为智能驾驶提供准确的位置和环境信息,帮助系统更好地感知周围环境并实现精准定位。虽然高精地图可以明显提升感知定位的精度,但也存在明显的不足,主要表现在以下三方面:第一,高精地图测绘的成本高、周期长,与主机厂降本增效的理念相悖。由于精度要求高、信息量丰富,高精地图厂商在制作高精地图时需配备各类传感器,相比普通导航会产生更高的成本和更长的周期,与当前行业内,尤其是智能驾驶领域的降本增效趋势严重不符。第二,高精地图的更新周期长,地图鲜度难以保障,甚至产生安全问题。智能驾驶对高精地图的数据实时性要求很高,也就是需要地图“保鲜”,最好能每日更新一次。而图商的平均更新周期以月或者季度为单位,行业内的平均更新周期3个月左右,这就导致图商提供的高精地图,难以满足智能驾驶开发的需求,甚至存在安全隐患,比如某路段新增了施工区域,而高精地图未及时更新,就可能会导致事故。第三,高精地图缺乏统一的行业标准。高精地图的内容、数据格式、发布传输、更新管理等尚未在行业内形成统一共识,缺乏统一标准,如果在开发过程更换了另一家高精地图供应商,会带来很多二次开发工作,严重影响项目进度,并且额外增加大量成本。正是由于高精地图的以上不足之处,目前行业内“去高精地图”成为一种趋势,甚至愈演愈烈。所谓无图,也就是不搭载高精地图的方案,完全依赖传感器实现感知与定位。无图方案的优势显而易见,不仅能够避免因地图鲜度不够导致的感知与定位错误,还能大幅降低开发成本和周期,尤其对于城市NOA来说,无图方案更容易快速实现大范围多区域的落地,“全国都能开”,而不会因地图的限制而进展缓慢。不过,由于感知能力的限制,如今行业内虽然“去高精地图”的声音很响,但其实国内的城市NOA方案中,要么还不能完全无图,要么无图的效果比有图差很远。目前,主要通过以下三种方式,来取代传统的高精地图:一是众包地图,即通过已售出车辆收集道路信息,整合来自广大普通用户的数据,绘制地图。众包地图具有较高的数据丰富度与实时性,并且成本低、覆盖范围广,但地图原始数据的质量参差不齐,精度和稳定性有待提升,并且存在数据合规和隐私保护等问题。二是实时局部建图,基于传感器信息,通过BEV+Transformer,构建实时的局部地图。这种方法理论上可以完全去掉高精地图,但根据大部分感知算法专家的意见,现阶段的环境感知效果,还达不到完全代替高精地图的水平,只能说正在逐步提升,向完全无图靠近。三是轻量化高精地图,是一种精简版的高精地图,精度和信息量介于导航地图与高精地图之间。这种方案可以理解为是一种过渡状态,是综合平衡整体感知定位效果与地图成本之后的结果,实际上仍然不是无图。 不难看出,“去高精地图”虽然是主机厂和智能驾驶开发者所推崇的趋势,但目前还没有完全实现。“去高精地图”,更多的是在摆脱对图商的依赖,而当前的环境感知效果,还不能达到完全无图的水平,即现阶段的城市NOA还不能完全离开高精地图,只是绘图的方式在改变,对精度的要求在降低。不过,随着BEV+Transformer的发展,视觉算法未来会有质的飞跃,而特斯拉FSD入华,也会带来新的“鲇鱼效应”,加快国内智能驾驶向无图方向演进。
纯视觉路线和多传感器融合路线,核心在于是否配置激光雷达,是否需要激光雷达的高精度点云信息,这也是行业内争论的焦点。纯视觉路线以特斯拉为代表,仅通过摄像头的视觉感知,实现对环境的精准识别;视觉+激光雷达以国内的多数厂商为代表,均采用带有激光雷达的配置方案。纯视觉方案主要依赖摄像头和计算机视觉算法,实现环境感知,与人眼观察环境相似。纯视觉方案由于不需要激光雷达,因此系统成本较低,但单一传感器的信息量和精度有限,且摄像头容易受天气和环境条件的影响,所以搭载激光雷达作为冗余和补充,是国内大部分厂商的选择。特斯拉是纯视觉方案的倡导者,其率先应用的BEV+Transformer纯视觉感知架构,能够将传统自动驾驶2D图像视角加测距的感知方式,转换为在鸟瞰图视角下的3D感知,有效提升智驾系统的感知精确度。另外,极越也采用了无激光雷达的纯视觉感知方案。多传感器融合方案将摄像头的图像数据与激光雷达的点云数据充分融合,能够有效提升环境感知的精度和抗干扰能力,提高系统的鲁棒性和可靠性。激光雷达不仅一度被称为“自动驾驶之眼”,而且也一直是国内大部分厂商实现城市NOA等高阶智驾的必备,但其高昂的成本(不低于2000元),导致难以大量普及,仅在高端或主打智驾功能的车型上搭载。当前国内激光雷达盛行的主要原因,还是在于视觉感知算法性能不足,纯视觉难以满足高阶智驾所要求的高精度、高实时性和高可靠性。可以认为,随着数据量的积累和计算机视觉的进步,以及BEV+Transformer等大模型的应用升级,纯视觉方案的效果会逐步提升,到时如果激光雷达不能把成本控制在千元以内,最终仍会被纯视觉方案所取代。
所以,纯视觉与多传感器融合的技术路线之争,本质上是视觉感知算法与激光雷达成本的进步速度之争,行业玩家理所当然地会平衡性能与成本,选择最佳性价比的方案。声明:除文内特殊声明外,本公众号内所有文章编写或转载的目的仅用于学习和交流,不予以商用,不代表本号观点及立场。本公众号内资讯及正文引用图片均由个人公众号 ADS 智库六耳基于官网或公开信息梳理或引用。本公众号所引用及转载内容版权均归原作者所有,凡是注明来源 “ XXX ADS 智库 ” 或作者为 “ XXX 六耳、XXX ADS 智库 ” 的文章转载或引用时请注明来源 ADS 智库。若有版权或其他任何问题请联系六耳( 微信号:adas_miao ),本号将及时处理。