GLM-Edge系列是智谱AI推出的一个专门针对端侧应用场景开发的大语言对话模型及多模态理解模型,包括参数规模为1.5B/4B的语言模型(GLM-Edge-1.5B-Chat、GLM-Edge-4B-Chat),以及参数规模为2B/5B的多模态模型(GLM-Edge-V-2B、GLM-Edge-V-5B)。其中,1.5B 和 2B 模型侧重于适配手机、车机等平台,4B和5B 模型则面向PC平台。GLM-Edge系列模型现已传至始智AI wisemodel开源平台,欢迎体验。https://wisemodel.cn/models/ZhipuAI/glm-edge-4b-chat-ggufhttps://wisemodel.cn/models/ZhipuAI/glm-edge-1.5b-chat-ggufhttps://wisemodel.cn/models/ZhipuAI/glm-edge-v-5b-ggufhttps://wisemodel.cn/models/ZhipuAI/glm-edge-v-2b-gguf在人工智能迈向落地应用的进程中,端侧大模型场景的开发与部署充满挑战。首先,难题是硬件限制。端侧设备,像手机、笔记本电脑这类,算力与内存远不及云端服务器。手机即便搭载高端芯片,面对复杂大模型运算,可承载参数量也很有限,不少高阶应用难以落地,限制了大模型端侧功能。其次,功耗问题突出,端侧设备多靠电池供电,续航备受重视。大模型运行能耗高,电量消耗快,设备得频繁充电,不符用户对长续航、便捷使用的需求。
第三,模型优化难度大,要将大模型部署到端侧,需量化、压缩。既要精简模型,适配有限硬件,又得保住性能、精度,把握好尺度很难,给模型设计与优化技术带来考验。
第四,适配性是一大挑战,端侧设备操作系统多样、应用生态碎片化,大模型融入时,实现流畅交互、功能调用不容易,当下多数模型与端侧系统还在磨合。数据隐私和安全很关键,端侧设备存有大量私人信息,大模型本地运行稍有差池就可能致数据泄露,危及用户权益。基于GLM-4系列的技术积累,智谱 GLM-Edge针对端侧实际部署情况,对模型结构和尺寸做了针对性的调整,以求在模型表现、实机推理效果和落地便利度之间达到平衡。同时,通过与伙伴企业的深入合作和在推理优化上的不懈努力,在一些端侧平台上,GLM-Edge系列模型能以极快的速度运行。
例如,在高通骁龙8 Elite平台上,借助其强大的NPU算力,GLM-Edge通过混合量化方案,1.5B对话模型、2B多模态模型能实现每秒60 tokens以上的解码速度。在应用投机采样技术之后,两个模型能以峰值每秒100 tokens以上的解码速度运行。与英特尔合作是关键一步,借助酷睿Ultra处理器性能,GLM-Edge模型推理效率大幅提升,实测超70 tokens/s,减少卡顿,交互流畅。功能上,GLM-Edge系列融合语言、多模态模型,可理解用户意图、实现对话交流、完成文本创作,还涉足视觉理解领域,适配多元场景。在隐私保护方面,GLM-Edge 也有相应举措。以端侧智谱清言为例,设有本地处理“隐私模式”,用户数据、私密文档均能得到妥善保护,降低隐私泄露风险。在生态构建上,GLM-Edge与华硕等 PC 厂商合作,推出AI PC智能助手。这一合作拓展了产品应用场景,利于端侧大模型在更多设备、业务里落地,推动端侧大模型生态逐步完善、走向成熟。GLM-Edge模型在多领域有着丰富实际应用案例。
在智能助手方面,智谱与英特尔携手,基于该模型不同参数规模的语言及多模态模型打造端侧智谱清言,赋予用户端侧高速推理的AI新体验,精准把握用户意图、流畅对话。
编程场景里,CodeGeeX AIPC版结合酷睿Ultra处理器与GLM-Edge模型,低功耗、高性能地助力程序员完成代码生成、补全等任务。
金融领域,它能深挖基金经理观点、市场评价等文本,提取关键信息,辅助投资者决策;游戏中,像GameSkills-无畏契约AI陪练,靠其强大语言生成力,帮玩家掌握进阶技巧。
此外,还用于图像识别,为图片分类、标注、描述,支撑图像搜索等应用;办公时实现文本自动生成、摘要提取、智能翻译;做智能客服时,精准理解用户问题、高效作答,提升客户满意度。
数据采集日截止到2024年11月28日。智谱还在积极与合作伙伴优化这些性能。首先在wisemodel上创建一个单卡A5000和3090的开发环境,选择基础开发镜像,选择模型文件/llm/ZhipuAI/glm-edge-4b-chat,填写好基本的信息,然后直接下一步,确认计费方式之后直接提交订单,开发环境就开始创建了。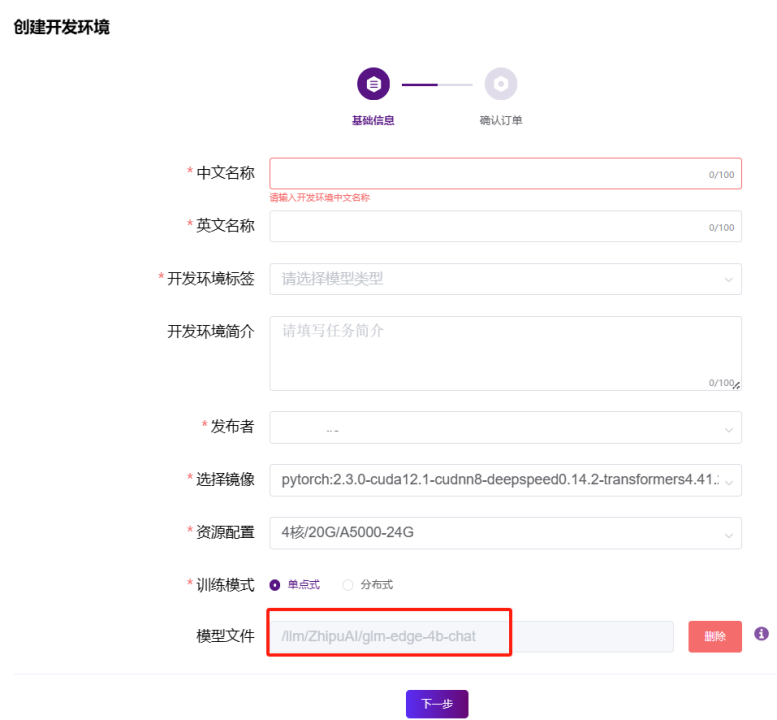
开发环境创建好之后,通过notebook或通过SSH登录到开发环境上进行部署相关的操作。
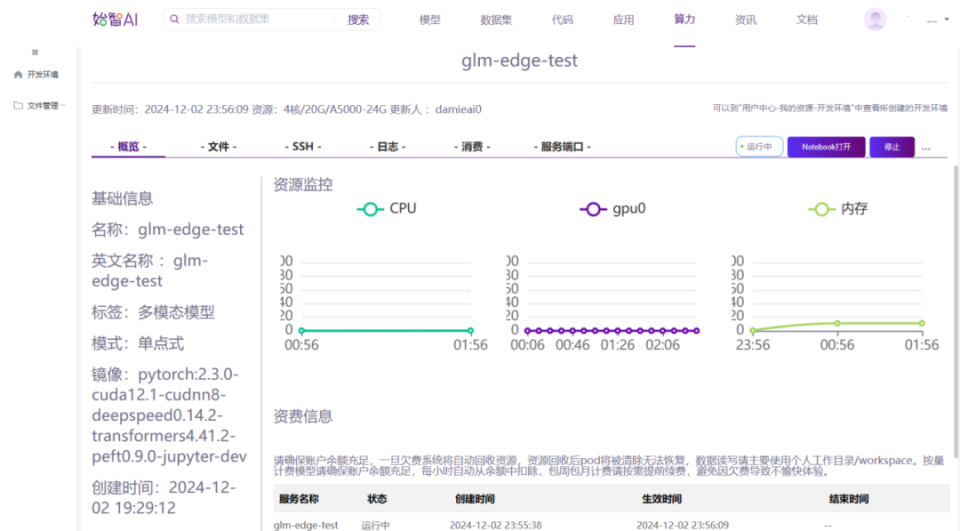
SSH登录到开发环境之后,先从github上把GLM-Edge的代码拉到开发环境。
代码下载好之后,先从hugging face仓库安装4.47版本transformer库再安装其他所需的库,安装命令如下:
pip install -r requirements.txt
安装好所需的库之后,先修改模型代码,路径为GLM-Edge下的./inference/web_demo.py,修改为以下3个地方:

模型部署的基本工作就完成,模型部署成功之后,回到开发环境详情的页面申请一个服务端口和域名地址。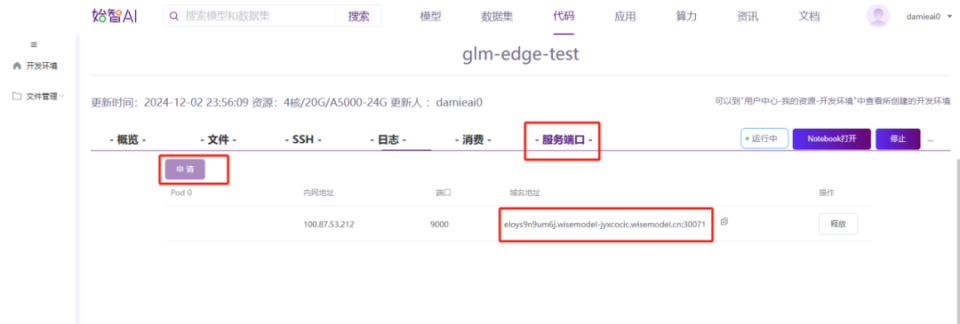
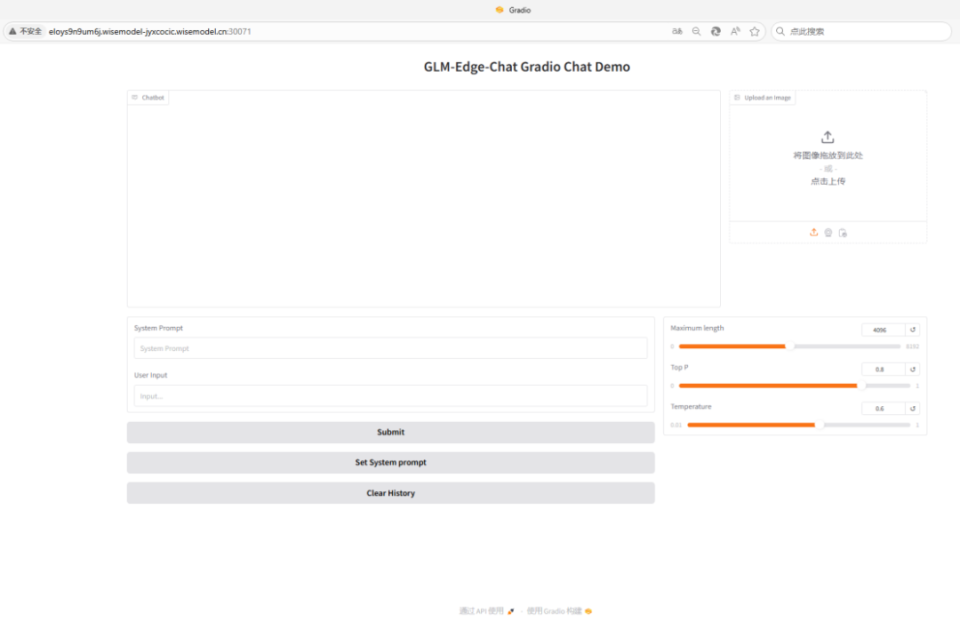
把申请好的域名地址复制到浏览器里,demo正常运行,就可以开始体验模型服务了。简单试了一下用GLM-Edge进行大模型对话非常不错。
作者:段枚佳