本文作者将介绍女娲对社区 ZooKeeper 在分布式读写锁实践细节上的思考,希望帮助大家理解分布式读写锁背后的原理。
在分布式系统中,通常会采用分布式锁来解决共享资源的互斥访问问题,而分布式读写锁则可以进一步提高读请求的并发。阿里云存储团队自研的分布式锁服务——女娲,凭借在性能、可扩展性和可运维性上的技术优势,使得阿里云存储在稳定、可靠、高性能等方面不断突破,进而为客户业务的永续运营提供了有力保障。在业界中,类似女娲的软件包括有 Apache ZooKeeper,Kubernetes Etcd,以及 Google Chubby,“他山之石,可以攻玉”,女娲的技术演进也在持续参考并吸收业界的最佳实践。本文,我们将介绍女娲对社区 ZooKeeper 在分布式读写锁实践细节上的思考,希望帮助大家理解分布式读写锁背后的原理。Apache ZooKeeper (下文简称 ZK)是开源社区一款比较知名的分布式协同软件,通过提供基础原语语义,开发者可以较为容易地开发出分布式锁、服务发现、元数据存储等关键的分布式管控功能。作为 Hadoop 生态圈早期成员,ZK 对业界的影响不可谓不深远。
除了常见的常规文件(Normal File)与临时文件(Ephemeral File),ZK 还提供了一种特别的顺序文件(Sequential File),业界知名的开源库 - Apache Curaor在 ZK 的顺序文件语义之上封装出读写锁、公平锁、分布式队列、分布式 Barrier 等诸多优雅功能。那么 ZK 的顺序文件是怎样实现的呢?ZK 顺序文件的创建依赖于其父目录节点的 cversion 属性。每个目录节点都会记录其子节点的创建和删除次数,此即为 cversion,当 ZK 收到创建顺序文件请求的时候,其会使用该文件父目录的 cversion 作为文件名的后缀,那么就可以保证先后创建的顺序文件后缀值是单调增加的。所谓无心插柳柳成荫,当初为订阅目录下节点增删事件所设计的属性,今后居然演变成了 ZK 场景下某种逻辑时间戳 ,孵化出了类似读写锁这样重要的功能特性。
如下图所示,譬如我们发送路径为“/vm/vsp-xxxxx/_READ_”的顺序文件的创建请求,后端实际创建的文件节点名为“/vm/vsp-xxxxx/_READ_0000000001”,之后再创建名为“/vm/vsp-xxxxx/_WRIT_”的顺序文件,后端实际创建的文件节点名为“/vm/vsp-xxxxx/_WRIT_0000000002”。如果我们把前者认为是读锁,那么就订阅“/vm/vsp-xxxxx/”目录下所有的节点,并且把子节点按照最后 10 位的后缀排序。如果发现不存在序号小于自身的写锁,那么自己就算是持锁成功了;如果我们把后者认为是写锁,那么就订阅“/vm/vsp-xxxxx/”目录下所有的节点,并且把子节点按照最后 10 位的后缀排序。如果发现不存在序号小于自身的读锁,也不存在序号小于自身的写锁,那么自己就算是持锁成功了。这样就实现了简单且优雅的分布式读写锁。类比单机系统中使用的读写锁,分布式读写锁对于业务运行性能上提升的意义,同样是不言而喻的。
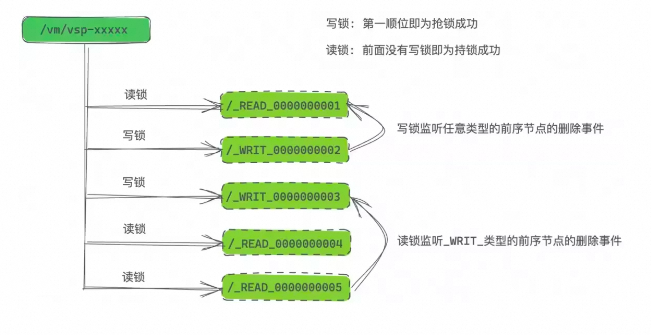
行文至此,大家应该也意识到,基于 ZK 实现的分布式读写锁,关键之处在于顺序文件(Sequential File)的后缀序号顺序性必须得到保障,即使在 failover 等场景下该序号顺序性也依旧严格维持。想象一下,ZK 系统当前认为“/vm/vsp-xxxxx”目录节点对应的 cversion 值为 5,然后 failover 之后,新当选的 Leader 认为 cversion 值为 4,那就糟糕了,可能就有新旧两个客户端自认为自己创建的顺序文件的序号都是 5,那么基于此特性实现的选主、抢锁等功能属性就会陷入「双主」、「一锁多占」等极其危险的境地,分布式存储的应用场景下,甚至会导致数据被写坏。这个也正是本文要探讨的重点,ZK 顺序节点的后缀序号的顺序性是如何得到保障的,特别是在 failover 等场景下是如何实现的?“谁能书阁下,白首太玄经”,通过对这个精巧案例的分析,也希望大家能够体会到女娲在分布式协调领域可谓“补天”般的苦心经营。ZK 是一个复制状态机模型,如下图所示,不同于存储 I/O 依赖链路上的 LSM-Tree 模型,ZK 的复制状态机是完全的内存模型,这样提供了最佳的访问性能(当然,这个也限制了 ZK 的存储容量,不过其定位即为状态管理,容量很难成为其瓶颈)。此外,复制状态机系统在使用共识协议保证事务日志一致性的基础上,工程实现时通常引入快照机制对事务日志进行必要的垃圾回收,以此加速 failover 恢复速度。对于 ZK 而言,为了不影响前台业务访问,其打快照过程必然得是异步的,即递归地遍历内存中 DataTree 的数据结构并持久化到磁盘上的快照文件。在打快照过程中,ZK 继续处理事务请求并更新到内存的 DataTree。换言之,实际持久化到磁盘上的快照文件,记录的是一个“混合”的系统状态,其并不真实存在于任何一个历史时刻。ZK 的复制状态机模型将其所有状态均在内存中维护再以下图为例,在 ZK 打快照过程中,实际上系统也在处理 op1、op2、op3 事务日志,这个带来了一个问题,当我们快照持久化了某个父目录节点(包括其 cversion 值),其下面的子节点在后续的持久化时刻,可能已经处理了新的 CREATE 或者 DELETE 等事务请求,导致快照中该父目录下实际孩子节点状态并非其记录父目录 cversion 所对应时刻的状态。相应地,在回放事务日志时候,状态机会先加载最新的快照文件到内存中作为初始版本的 datatree,而后根据快照中维护的开始打快照时刻对应的事务日志序号,往后一条一条地回放事务日志,对应图中即为从 op1 开始,逐条日志回放。所以,即使持久化的快照中可能已经包含了执行完 op1、op2、op3 之后的状态,在回放的时候仍然会重新再执行一遍这些事务日志。这是大部分异步打快照的系统普遍面临的问题,对于 ZK 来说,需要在回放事务日志重建内存状态过程中合理应对。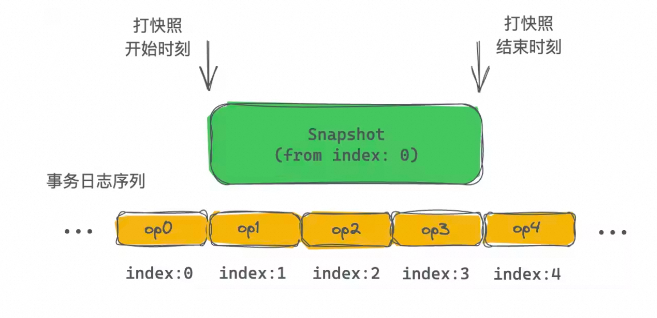 ZK 的快照实际上持久化的是一个“混合”的系统状态因为 ZK 是个幂等的系统设计,因此 failover 场景下在回放事务日志时候,即使存在部分重合的日志应用(APPLY)至状态机,这里是没有数据正确性风险的。但是对于 failover 场景下重新计算出最新的 cversion 值则存在大挑战。考虑如下图的这种情况,快照在 index:2 执行完才开始序列化父目录,此时记录的父目录 cversion 值为 2,后继时刻 3 开始持久化子节点,此时快照记录的子节点只有“/root/B”。
ZK 的快照实际上持久化的是一个“混合”的系统状态因为 ZK 是个幂等的系统设计,因此 failover 场景下在回放事务日志时候,即使存在部分重合的日志应用(APPLY)至状态机,这里是没有数据正确性风险的。但是对于 failover 场景下重新计算出最新的 cversion 值则存在大挑战。考虑如下图的这种情况,快照在 index:2 执行完才开始序列化父目录,此时记录的父目录 cversion 值为 2,后继时刻 3 开始持久化子节点,此时快照记录的子节点只有“/root/B”。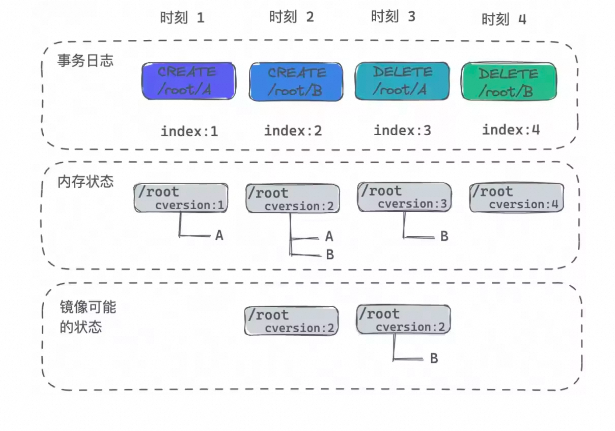 幂等的快照设计给目录 cversion 维护带来挑战那么这个例子下 failover 恢复的步骤是怎么样的呢?请看下表,最终恢复出来的目录 cversion 值正确,并且孩子节点信息也是正确的。实际上,按照这个步骤最终恢复回来的 cversion 不会小于 failover 之前的 cversion,因为无论如何 cversion 总是会在快照的起始 index 之后才被写入的快照文件,而后继回放事务日志时,每次创建和删除也都使 cversion 递增,所以最终的 cversion 值一定大于等于 failover 之前内存所维护的 cversion 值。
幂等的快照设计给目录 cversion 维护带来挑战那么这个例子下 failover 恢复的步骤是怎么样的呢?请看下表,最终恢复出来的目录 cversion 值正确,并且孩子节点信息也是正确的。实际上,按照这个步骤最终恢复回来的 cversion 不会小于 failover 之前的 cversion,因为无论如何 cversion 总是会在快照的起始 index 之后才被写入的快照文件,而后继回放事务日志时,每次创建和删除也都使 cversion 递增,所以最终的 cversion 值一定大于等于 failover 之前内存所维护的 cversion 值。