随着年初OpenAI 的Sora demo的发布,视频生成或视频编辑领域呈现出井喷式发展的趋势。这一新兴技术浪潮不仅吸引了众多研究人员的目光,也使得相关应用如雨后春笋般涌现,为整个行业带来了前所未有的创新活力。
本文将从几个方面具体分享关于视频编辑方法StableV2V研究的心路历程,包括视频编辑基本定义、视频编辑现有方法的解决方案及局限性,以及StableV2V的思路和实现细节等。目前StableV2V模型已上线始智AI-wisemodel开源社区,欢迎大家前去体验。
模型和代码地址:
https://wisemodel.cn/models/Alonzo/StableV2Vhttps://wisemodel.cn/codes/Alonzo/StableV2V视频编辑(video editing)这项任务旨在根据用户输入的额外条件,对原视频中的内容(例如:前景、背景等等)进行编辑。在diffusion model主导的大背景环境下,现有方法的setting大多都是基于文本描述进行的,比较有名的工作有TokenFlow、StableVideo、AVID等等。
也就是说,这类方法往往会需要两个输入——原视频的text prompt以及编辑后视频的text prompt——并且这两个text prompt之间往往仅有极个别描述视频主体(物体、背景)的词语区别。除此之外,也有基于image prompt的方法,例如VASE,呈现出的效果大致类似于图片模态中的subject-driven generation。这些方法也就形成了目前video editing的两大主流settings——text-based和image-based editing。下面两个具体例子让大家能够更直观地感受这两种setting的具体效果:Image-based editing效果的演示(右下角展示为reference image)其实从上述两个例子,大家不难发现video editing这个任务的难点——(1)生成视频帧之间的连续一致性、(2)编辑内容与user prompts之间的一致性问题。第一点可以说是视频模态相关任务的通病——即我们常说的temporal consistency问题。
也就是说,我们在对原视频进行编辑的同时,也要保证生成视频帧与帧之间是连贯的;第二点则是由于人机交互带来的问题,我们知道,用户在交互过程中给定的prompt(文字或图片),往往会存在跟生成内容之间不一致的问题。
具体来说,这一点可以是模型不能生成出text中描述的内容,亦或是因为模型范式本身存在的问题,生成的内容难以让人满意。据我们观察,这类现象是相当普遍的,尤其是当用户期望生成的内容,与原视频的内容之间有较大形状差异。例如,上图中用户给定了的「斑马」的prompt,但VASE由于其自身的特性,仅能生成「牛形状的斑马」,这样的效果肯定不会是我们需要的。于是,StableV2V基于上述我们观察到的不一致问题为研究动机,展开了对现有方法的调研、综述、反思、及改进。我们将现有方法分为四类:基于DDIM inversion的方法、基于one-shot tuning的方法、基于学习的方法(learning-based)、基于第一帧编辑的方法。在本章中,我们将详细讨论这些方法的做法,以及它们对于前述问题存在的局限性。
基于DDIM inversion的方法旨在将原视频通过DDIM inversion的方式,获得每个timestep对应的特征(CNN features、attention maps)等,然后再在扩散模型采样时对每一步的对应特征将这些抽取出来的原视频特征整合进去。这样的做法其实很直观,就是想将原视频的运动模式对采样过程进行一定程度的引导,从而让输出视频在生成新的编辑内容的基础上,在其余内容上与原视频保持一致。具体来说,现在比较常用的一个思路是将PnP(Plug-and-Play Diffusion Features)的思路用到视频里来(AnyV2V的做法),或者是通过一些一致性的约束设计让生成视频与原视频保持一致性(TokenFlow的做法)。PnP是一个image editing工作,通过在采样过程中替换CNN features和attention maps,让编辑的内容与原图像保持一致。TokenFlow的流程图,通过最近邻去匹配相似的attention maps,并在采样过程中用这些attention maps去约束生成视频。基于one-shot tuning的方法旨在训练一个video-specific的模型权重,通过这个权重对视频的motion patterns进行建模,然后在采样过程中通过调整text prompt的方式生成不同的结果,比较经典的代表作有ICCV 2023的Tune-A-Video,以及后续将prompt2prompt的思路和one-shot tuning整合到一起的Video-P2P。
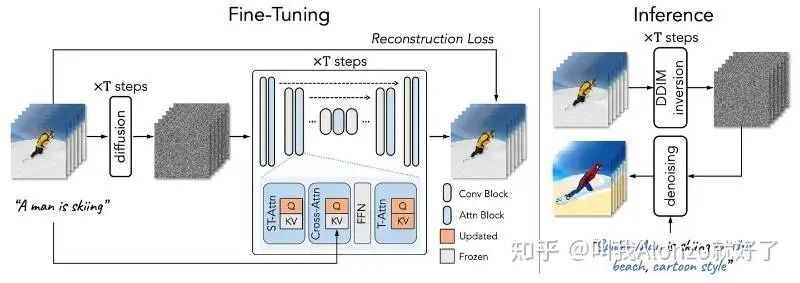
但值得注意的是,前述这两种方法很大程度上受限于原视频的motion patterns—也就是说,它们只能处理「编辑内容」与「原视频内容」形状相似的场景—否则的话,这些从原视频中抽取出来的motion信息,在用在新编辑的内容上时,会存在不匹配的问题,尤其是前文中讲到的user prompts期望的内容会导致形状变化的场景。相反,基于学习的方法旨在通过微调image diffusion models,通过类似AnimateDiff的范式,往image diffusion models中插入motion modules,再在大规模的文本-视频数据集上进行微调这些motion modules,以此赋予模型编辑视频的方式。但是,基于学习的方法很大程度受限于image diffusion models的范式——也就是它们的inpainting架构。比方说,AVID是从SD Inpaint开始微调的;VASE是从Paint-by-Example。这些inpainting model在用户输入原视频、text prompt之外,还会要求输入编辑区域对应的mask。而这样的mask,通常是依赖于数据集标注(例如VOS数据集),或者需要进行人工标注的,这样的标注过程将会变得非常费时费力。尤其是在处理前文中说到的场景,用户不能知道编辑的内容会生成在什么位置,因此也不能够给出精准的mask标注。
最后一类方法是基于第一帧编辑的方法,也是近期比较新颖的一类范式,代表性的工作有AnyV2V。这类方法将video editing分成两个步骤,先对视频的第一帧进行编辑,然后通过motion transfer的方式,将第一帧编辑的内容扩散到剩余的视频帧上去,为video editing提供了非常强大的灵活性。现有相关工作有AnyV2V和I2VEdit,然而,AnyV2V采取的motion transfer思路是前文介绍的DDIM inversion + PnP的范式,I2VEdit则是基于one-shot tuning的范式,这两者均会受限于原视频内在的motion patterns。这样的研究背景不由得引发了我们对video editing的思考——究竟什么样的范式才能够解决好video editing中编辑内容与user prompts不一致的问题?在设计StableV2V的时候,我们尝试跳出现有方法的范式局限,专注于思考一个问题——我们究竟能不能拿到跟user prompts对齐的motion patterns?
其实在早期研究的时候,我们也尝试过前述几种方法的范式,但最终都苦于不能仿真出与user prompts对齐的motion patterns,生成的结果往往不尽人意。但是我们始终清醒的认识到一点—如果我们基于第一帧编辑的范式去设计StableV2V,那么我们是能拿到跟user prompts对齐的内容的—也就是编辑之后的第一帧对应的信息。如果我们能找到一个方式,从这一帧的信息出发去仿真得到其他帧的信息,那么肯定是能拿到对齐的motion patterns的。基于这个思路,我们最终将StableV2V呈现在了大家面前:StableV2V的方法流程图。图中的绿框代表视频的第一帧,蓝框代表从第k次迭代仿真到第k+1次仿真的过程。
StableV2V主要包括三个核心组件—Prompted First-frame Editor(PFE)、Iterative Shape Aligner(ISA)、Conditional Image-to-video Generator(CIG)。
简单来说,Prompted First-frame Editor(PFE)主要负责将user prompts转换成编辑后的第一帧。这里我们考虑了目前开源的诸多图像编辑工作,例如Paint-by-Example、SD Inpaint、InstructPix2Pix等等,同时发现,通过调整PFE,能够实现text-based editing、instruction-based editing、image-based editing等多种主流的video editing设定,甚至我们的方法能够进行很多有趣的应用——例如跟用户手画的sketch进行交互。StableV2V的核心组件是Iterative Shape Aligner(ISA),也就是我们将模型使用的motion patterns与user prompts对齐的组件。前文我们说到,我们能够拿到的第一编辑帧的信息,是与编辑视频对齐的。基于这点,我们考虑到深度图能够对视频运动的motions和形状同时进行表征,于是采用深度图作为传递motion patterns的中间媒介;并且,我们观察到编辑后的物体(即使有较大形变),与原视频中的内容也应该保持一样的motion——也就是说,编辑后物体的光流与原视频的「光流」及「深度图」应该保持一样的数值。基于这点,我们找到了仿真编辑视频对应的深度图的方法。Motion Simulation。具体来说,ISA需要借助「原视频帧」以及「第一编辑帧」对应的segmentation masks来完成仿真过程,这里我们仅介绍从第1到第2个仿真的光流仿真过程(上图中的红色框部分),后续的过程以此类推,展示如下:
首先,我们会计算「原视频光流」在对应segmentation mask中的均值,并以此来表征「原视频物体的运动信息」;由于编辑后物体的光流与原视频的「光流」及「深度图」应该保持一样的数值,并且我们能够拿到第一编辑帧对应的segmentation mask,我们将前述计算得到的「平均光流值」,赋值到第一编辑帧segmentation mask对应的区域,我们将这一过程称为motion pasting,仿真后的光流与原光流进行拼接,就能得到「编辑视频第1帧到第2帧的光流」;在拿到编辑视频第1帧到第2帧的光流」后,我们将「第一编辑帧的segmentation mask」warp到下一帧,拿到第2帧对应的segmentation mask;至此,我们已经具备了从第2帧到第3帧进行仿真的所有输入条件(即原视频光流、原视频segmentation mask、第2编辑帧对应的segmentation mask),因为我们可以通过一种迭代式的仿真方式获得最终视频对应的仿真光流。Depth Simulation。一旦我们拿到了最终视频对应的光流信息,下一步就是仿真对应的深度信息,仿真深度信息的过程与仿真光流的过程类似,在此不再具体展开,感兴趣的朋友欢迎移步原文。Shape-guided Depth Refinement。到这一步,我们已经拿到了一个仿真的深度图,但是值得注意的是,这样仿真出来的深度图往往会有原视频中的冗余信息,例如StableV2V方法流程图中多余的天鹅部分。如果我们用这样的深度图去引导视频生成网络,那么输出的视频中肯定会存在由于不一致导致的artifacts。受到video inpainting研究的启发,我们提出了一个形状引导的深度图修复网络来解决这个问题,旨在将冗余的深度图部分移除。下面我们可视化了前述各个阶段仿真的深度图效果,大家可以直观地看到,最终送入视频生成网络的深度图与编辑后的内容是一致的,并且,我们很庆幸的是我们的方法具有不错的精度,能有效保留编辑后物体的形状一致(例如下图中的葡萄)。最后,Conditional Image-to-video Generator(CIG)作为一个深度图引导的图生视频网络,旨在通过「第一编辑帧」和「修复后的深度图」将编辑的内容扩散到其他的视频帧上去,以生成最终编辑后的视频。另外,我们观察到现有方法大多在自己搜集到的测试集上对模型的性能进行验证,因为我们提出了一个基准测试集,名为DAVIS-Edit,数据集已在我们的HuggingFace repo中开源,包含人工标注的text prompts和image prompts为两大主流settings提供了测试标准。同时,DAVIS-Edit提供了两套标注,一套对应编辑后物体与原视频物体相差不大,另一套则会有较大的形状差异,以此来推动更多相关的研究。我们在文章中对StableV2V以及七个现有方法进行了对比。客观指标上,我们考虑了DOVER、FVD、WE、CLIP-Temporal、CLIP score、推理时间,从视频质量、帧间一致性、图文对齐、推理效率等多个方面对现有方法进行评测。
同时,我们还考虑了human evaluation。关于实验结果的对比及分析,欢迎大家参考我们的原文。下面是我们主实验的结果:
StableV2V与其他方法在DAVIS-Edit上的对比结果
更多的可视化生成结果,欢迎大家移步我们的项目主页,我们提供了视频格式的结果、应用、及对比。下面我们展示一些图片格式的结果预览:StableV2V在text-based editing(左)和image-based editing(右)上的应用